![]()
顺序单发六级流水线标量处理器-RV64GC cva6(Ariane)
cva6系列(一) 处理器解析
预计更新到魔改其为多发超标量乱序核,悠闲的日子快过去了,咕咕咕多久未知(reference:
kaitoukito: Ariane处理器源码解析系列
sazc: cva6架构概述
cva6 github仓库
The Cost of Application-Class Processing: Energy and Performance Analysis of a Linux-ready 1.7GHz 64bit RISC-V Core in 22nm FDSOI Technology
总览
PULP(Parallel Ultra-Low-Power) 平台在2019年启动了 Ariane 开源处理器项目,由 OpenHW Group 维护,后改名为cva6。
cva6 core 是一个可配置的 core,在典型64bit配置下,cva6 是一个 RV64GC ISA、6-stage 顺序单发射 64bit CPU core,完全实现了 Volume I: User-Level ISA V 2.1 中指定的 I、M 和 C 扩展以及 draft privilege extension 1.10,且实现了三个特权级 M、S、U 以完全支持类Unix操作系统,这是通过实现 39-bit 基于页的虚拟内存策略(SV39)来做到的。
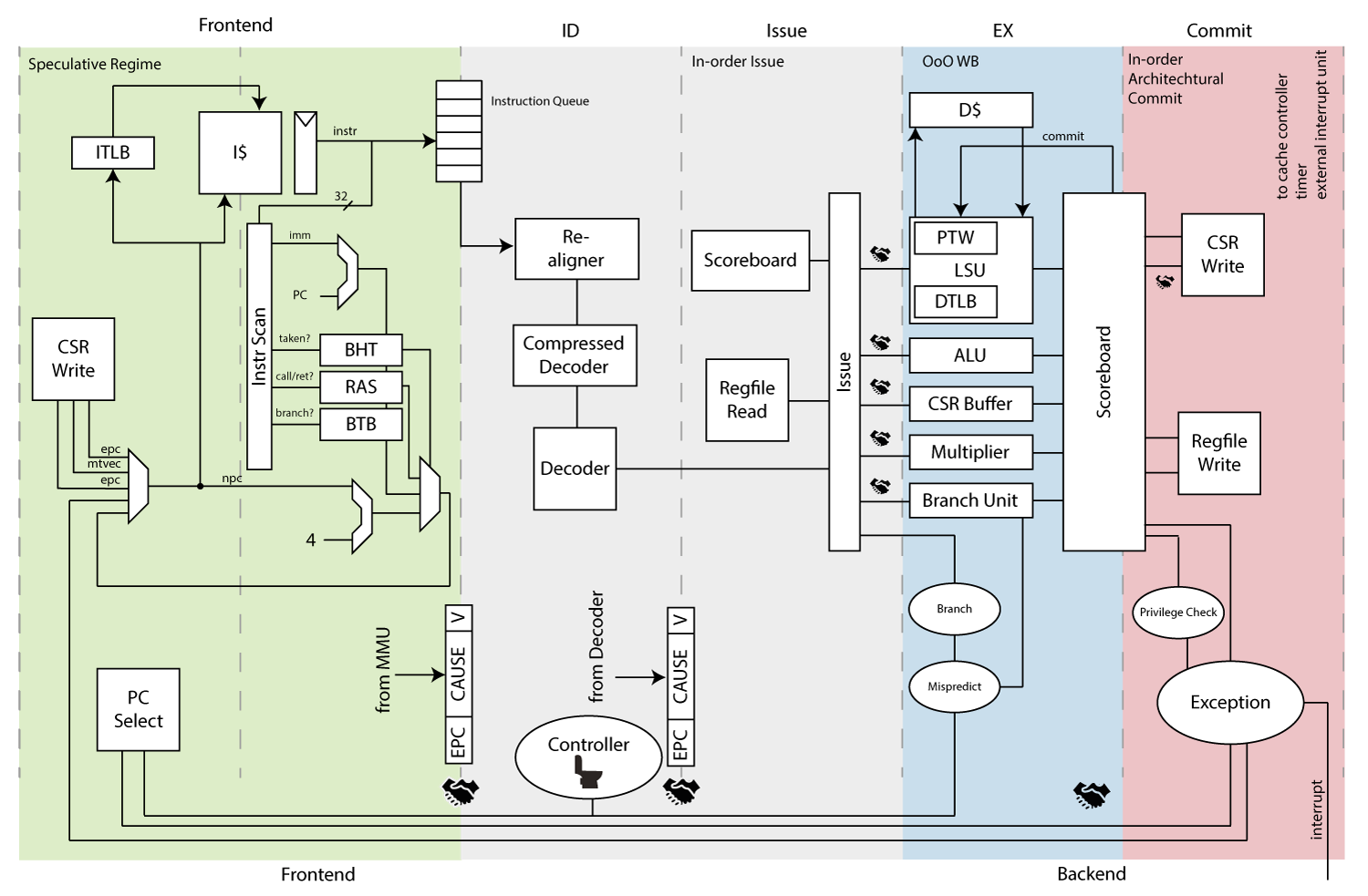
该图与最新项目版本有差异
PULP 平台的设计理念之一就是低功耗,所以目前还没有见到 Superscalar & OoO 的 CPU core 项目,cva6 作为PULP-RVcore系列的性能大哥,它的设计目标也很纯粹简单:以合理的速度和 IPC 运行完整的OS,为达到必要的速度,core采用 6-stage 流水线设计。为了提升 IPC,core 使用了记分板技术(scoreboard),该记分板应通过发布与数据无关的指令来隐藏data RAM(cache)的延迟。instruction RAM(or L1 I-cache)在命中时有1个周期的访问延迟,而访问数据 RAM(or L1 D-cache)在命中时有3个周期的延迟。core 拥有独立的 TLBs,一个硬件 PTW和基于分支预测(BHT(PHT)+BTB)的推测执行机制,设计的首要设计目标是减少关键路径长度,同时保持每周期指令(IPC)损失适度。目标逻辑深度被选择为低于30个 NAND Gate Equivalents(GEs),这仅比最先进的、高度适配的、服务器级的乱序处理器高两倍。
处理器总览
- RV64GC
- 实现了RV64IMAFDC(RV64GC),即支持整数指令I、整数乘除M、单精度浮点F、双精度浮点D、原子指令A、压缩指令C(一个可以运行的RISC-V处理器仅支持整数指令集I即可,其他均为配置选项。)
- 6级流水线
- PC Generation—PC生成级
- Instruction Fetch—取指级
- Instruction Decode—指令译码级
- Issue—指令发射级
- Execute—指令执行级
- Commit—指令提交级
- 流水线的动态调度
- Scoreboard:计分板技术,起源于1965年交付的CDC6000,记录并避免WAW、WAR、RAW数据依赖性,通过动态调度流水线的方式,实现乱序执行,提高流水线效率
- Register renaming:寄存器重命名,解决数据依赖性问题,支持乱序执行,但cva6暂未完全实现
- 动态分支预测
- BTB:branch target buffer,类似cache结构的分支目标缓冲区,与cache不同的地方大概是用于索引表项的Tag为压缩后的PC/历史信息,功能为缓存预测的分支目标地址
- BHT:branch history table 基于2bit饱和计数器的模式历史表(PHT),这两个名字指代同一个部件,功能为预测跳转方向
- RAS:return address stack 分支返回栈(aka RSB,return stack buffer),功能为存储最近的系统调用指令地址,遇到ret指令时弹出存储的地址
- OS 支持
- 实现了RISC-V的三种特权模式,分别是机器模式M-Machine Mode、监督模式S-Supervisor Mode、用户模式U-User Mode
- 拥有ITLB、DTLB、PTW实现虚拟地址到物理地址的快速翻译
- 拥有可灵活配置的4路组相连L1-ICache与L1-DCache
本文选择的 core configuration 为项目工程中core/include/cv64a6_imafdc_sv39_config_pkg.sv配置文件,并使用RISC-V sv39虚拟内存系统:
package cva6_config_pkg;
typedef enum logic {
WB = 0,
WT = 1
} cache_type_t ;
localparam CVA6ConfigXlen = 64;
localparam CVA6ConfigFpuEn = 1;
localparam CVA6ConfigF16En = 0;
localparam CVA6ConfigF16AltEn = 0;
localparam CVA6ConfigF8En = 0;
localparam CVA6ConfigFVecEn = 0;
localparam CVA6ConfigCvxifEn = 1;
localparam CVA6ConfigCExtEn = 1;
localparam CVA6ConfigAExtEn = 1;
localparam CVA6ConfigBExtEn = 1;
localparam CVA6ConfigAxiIdWidth = 4;
localparam CVA6ConfigAxiAddrWidth = 64;
localparam CVA6ConfigAxiDataWidth = 64;
localparam CVA6ConfigFetchUserEn = 0;
localparam CVA6ConfigFetchUserWidth = CVA6ConfigXlen;
localparam CVA6ConfigDataUserEn = 0;
localparam CVA6ConfigDataUserWidth = CVA6ConfigXlen;
localparam CVA6ConfigRenameEn = 0;
localparam CVA6ConfigIcacheByteSize = 16384;
localparam CVA6ConfigIcacheSetAssoc = 4;
localparam CVA6ConfigIcacheLineWidth = 128;
localparam CVA6ConfigDcacheByteSize = 32768;
localparam CVA6ConfigDcacheSetAssoc = 8;
localparam CVA6ConfigDcacheLineWidth = 128;
localparam CVA6ConfigDcacheIdWidth = 1;
localparam CVA6ConfigMemTidWidth = 2;
localparam CVA6ConfigWtDcacheWbufDepth = 8;
localparam CVA6ConfigNrCommitPorts = 2;
localparam CVA6ConfigNrScoreboardEntries = 8;
localparam CVA6ConfigFPGAEn = 0;
localparam CVA6ConfigNrLoadPipeRegs = 1;
localparam CVA6ConfigNrStorePipeRegs = 0;
localparam CVA6ConfigInstrTlbEntries = 16;
localparam CVA6ConfigDataTlbEntries = 16;
localparam CVA6ConfigRASDepth = 2;
localparam CVA6ConfigBTBEntries = 32;
localparam CVA6ConfigBHTEntries = 128;
localparam CVA6ConfigNrPMPEntries = 8;
localparam CVA6ConfigPerfCounterEn = 1;
localparam CVA6ConfigDcacheType = WT;
localparam CVA6ConfigMmuPresent = 1;
`define RVFI_PORT
// Do not modify
`ifdef RVFI_PORT
localparam CVA6ConfigRvfiTrace = 1;
`else
localparam CVA6ConfigRvfiTrace = 0;
`endif
endpackage
Frontend(处理器前端流水线)
PC Generation
PC生成级负责选择下级程序计数器(next PC)。这可能来自异常返回时的控制和状态寄存器(CSR)、调试接口、错误预测的分支或连续的指令提取。
所有PC都是逻辑寻址(虚拟地址,VA)的,如果逻辑地址到物理地址的映射改变了,那么应该用一条sfence.vma指令来flush流水线和TLB(Translation Lookaside Buffer)
该流水级包含对分支预测目标地址的推测和分支是否跳转信息,此外,它还包含分支目标缓冲区(BTB)和分支历史表(BHT)。如果 BTB 将certain PC解码为跳转指令(Jump),则 BHT 决定该分支是否跳转。由于各种全状态内存组件,此阶段分为两个流水线阶段。PC Gen 通过握手信号与 IF 通信。指令提取通过断言就绪信号表示其准备就绪,而 PC Gen 通过断言信号fetch_valid表示有效请求.
next PC有以下来源(按照顺序给出,数字越大优先级越高)
- Default assignment:默认分配是获取
PC + 4,PC Gen 始终字节对齐(32-bit)取指,压缩指令后续的流水线步骤中处理 - Branch Predict 分支预测:如果 BHT 和 BTB 把 certain PC 预测为一个分支指令,PC Gen 将
next PC设置为预测地址,并通知 IF-stage 已对 PC 执行了预测。这在流水线下游的各个地方都需要(例如纠正预测)。向流水线后级传递的分支信息被封装在一个名为branchpredict_sbe_t的结构。 与其相反的是向流水线前级传递的分支预测信息bp_resolve_t。这用于纠正动作(见下一个next PC来源)。这种命名习惯可以很容易地检测源代码中的分支信息流。 - Control flow change request 控制流改变请求:控制流更改请求是由于分支预测器预测错误而发生的。这可能是“真正的”错误预测,也可能是未被识别的分支。在任何情况下,我们都需要更正我们的操作并从正确的地址开始获取。
- Return from environment call 环境调用返回:一个环境调用返回执行 PC 的纠正操作,将
successive PC设置为存储在[m|s]epc寄存器中的 PC。 - Exception/Interrupt 异常/中断:如果发生异常(或中断,这俩在RV系统上下文中非常相似),PC Gen 将生成
next PC作为陷阱向量基地址(trap vector base address)的一部分。陷阱向量基地址可以不同,具体取决于异常是陷入到 S-Mode 还是 M-Mode(当前不支持用户模式异常)。CSR单元的目标是找出陷阱的位置并将正确的地址呈现给 PC Gen。 - Pipeline Flush because of CSR side effects:当写入具有 side-effects 的
CSR时,我们需要刷新整个流水线并再次从下一条指令开始获取,以便考虑更新的信息(如虚拟内存基址指针(virtual memory base pointer)变化)。 - Debug 调试:调试具有最高的优先级,因为它可以中断任何控制流请求。它也是控制流变化的唯一来源,它实际上可以与任何其他强制控制流变化同时发生。调试单元报告改变PC的请求和CPU应该改变到的PC。
PC Gen 单元还负责一个名为fetch_enable的信号,其目的是在未断言时阻止取指令。另需注意的是,这个单元不会发生流水线冲刷,所有刷新信息均由控制器分发,实际上控制器的唯一目的是刷新不同的流水级。
分支预测机制
cva6的BPU非常朴素,后续直接结合代码来解析,未完待续...