20世纪的乱序超标量处理器:MIPS R10000(R10k)
再次看到R10k,已经是23年的5月份了。回想起硕士刚进课题组调研BOOM的时候,观察到了UCB的团队给予了该处理器崇高的敬意,宣称R10k给BOOM的设计开发工作提供了许多灵感。当初在几乎一片空白的知识体系下翻译了这篇论文,有很多谬误和不专业的地方恳请各位看官原谅!
借此整理博客的机会,把之前的文字也重新整理,(有些当时绘制的图已经找不到了)回顾一下这颗古老的,跨时代设计的艺术品。Reference:
Yeager, Kenneth C. "The MIPS R10k superscalar microprocessor." IEEE micro 16.2 (1996): 28-41.
处理器总览
- 四路超标量 RISC 处理器
- 每周期取指并译码四条指令
- 基于分支预测的推测执行技术,4-entry的分支栈
- 动态乱序执行技术
- 利用映射表实现寄存器重命名
- in-order graduation for precise exceptions
- 五条独立的流水线执行单元
- 一个非阻塞 Load/Store 单元
- 64位 INT ALU * 2
- 64位 IEEE 754-1985 FPU
- 2-cycle 流水线加法器
- 2-cycle 流水线乘法器
- 层次化、非阻塞的内存子系统
- 片内、2-way L1缓存
- 32Kb Icache
- 32Kb Interleaved Dcache
- 片外、2-way L2缓存
- 128bit-wide, 同步SRAM
- 64bit 多核系统接口(带分离事务协议)
- 片内、2-way L1缓存
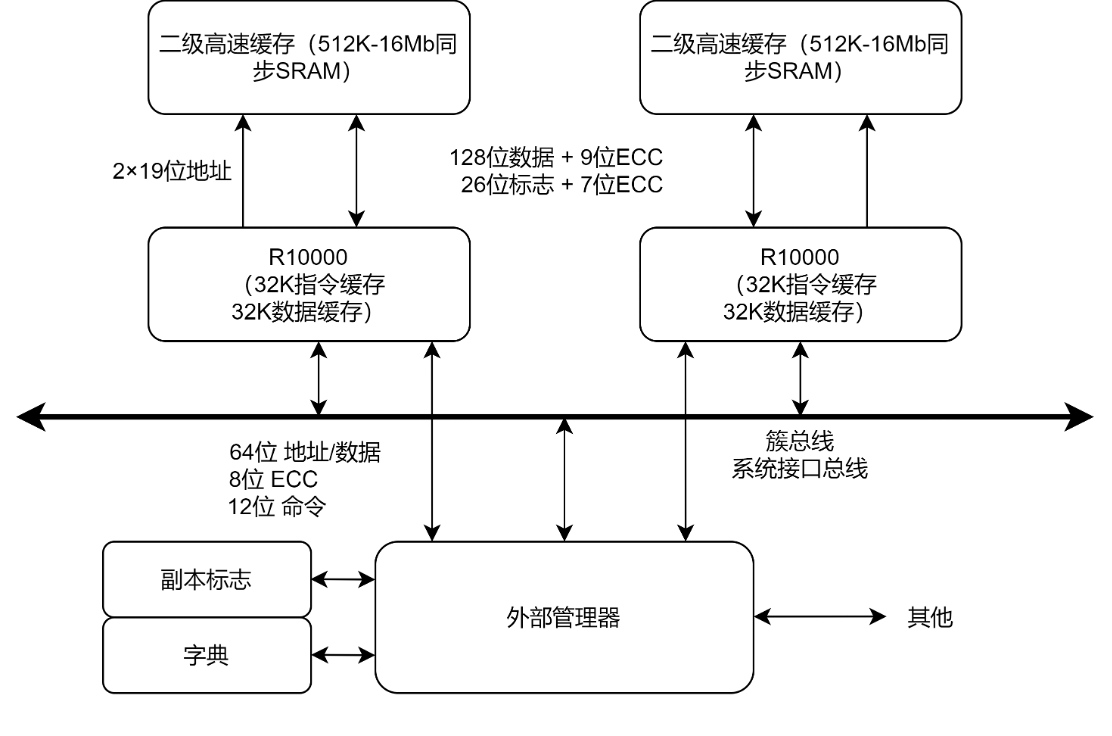
系统灵活性
通过不同的配置,R10k可以在一个宽范围系统中工作——单核处理器或多核处理器(集群)。系统使用snoopy或directory方案来维护缓存一致性。R10k的L2缓存范围在512K字节到16M字节之间。
概述
两张图为R10k的组成框图和流水线时序图,共有近6条独立流水线。
取指流水线位于第1至3级,在第1级R10k获取并对齐后续四条指令;在第2级,进行译码并对齐后续四条指令,在第2级,进行译码并对这些指令进行重命名,还对其中的跳转和分支指令计算目标地址。在第3级,将重命名后的指令写入队列。同时读取忙位表(busy-bit table)来判断。
操作数是否处于忙状态,指令将在队列中等待直到其所有操作数就绪。
在第三级,当队列发射一条指令,则其后的五条执行流水线就开动了。处理器在第3级的后半段从寄存器文件中读取操作数,并从第4级开始执行,整数流水线占据一级,装载流水线占据两级,浮点流水线占据三级,处理器在下一级前半段将结果写入寄存器文件。
整数和浮点部分有不同的指令队列、寄存器文件和数据通道。分离是为了减少最大线长(wire length),获得完全的并行操作。分开后的两个寄存器文件比组合在一个单元里需要更多的空闲寄存器。但由于每个寄存器只需要少量读写端口,因此,物理上来说面积会更小。
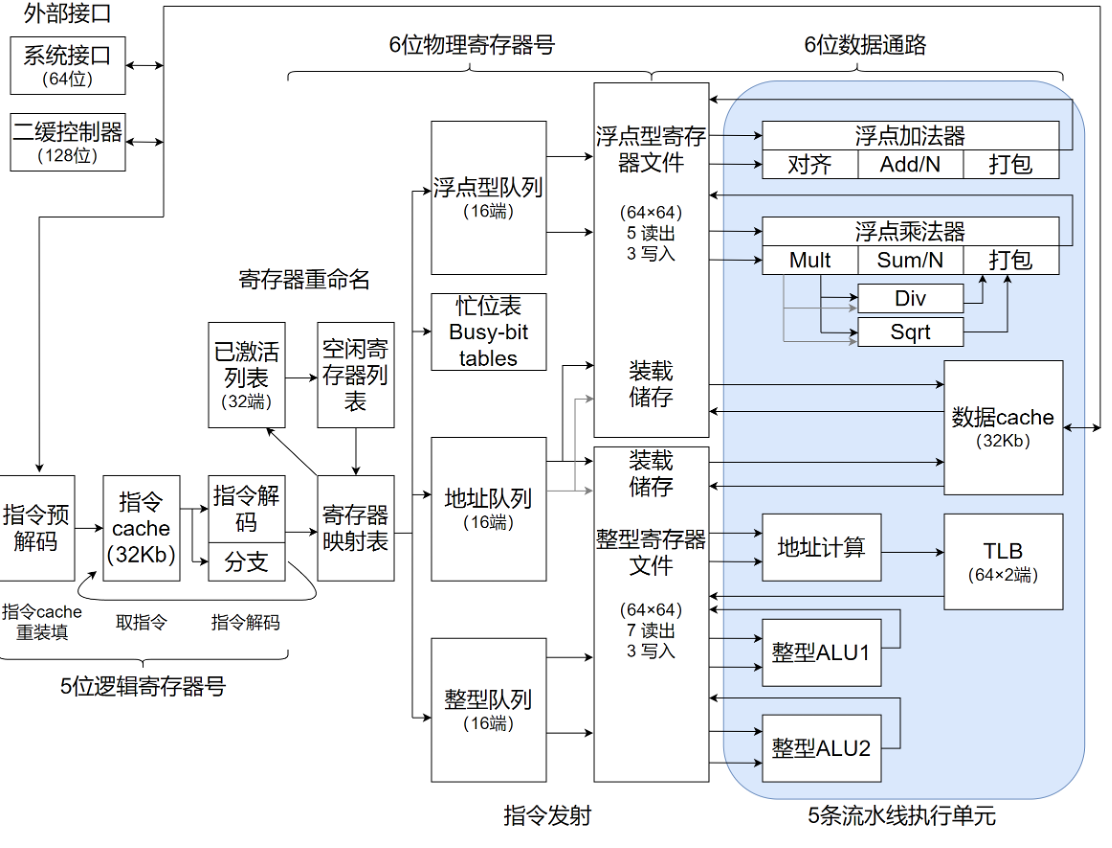
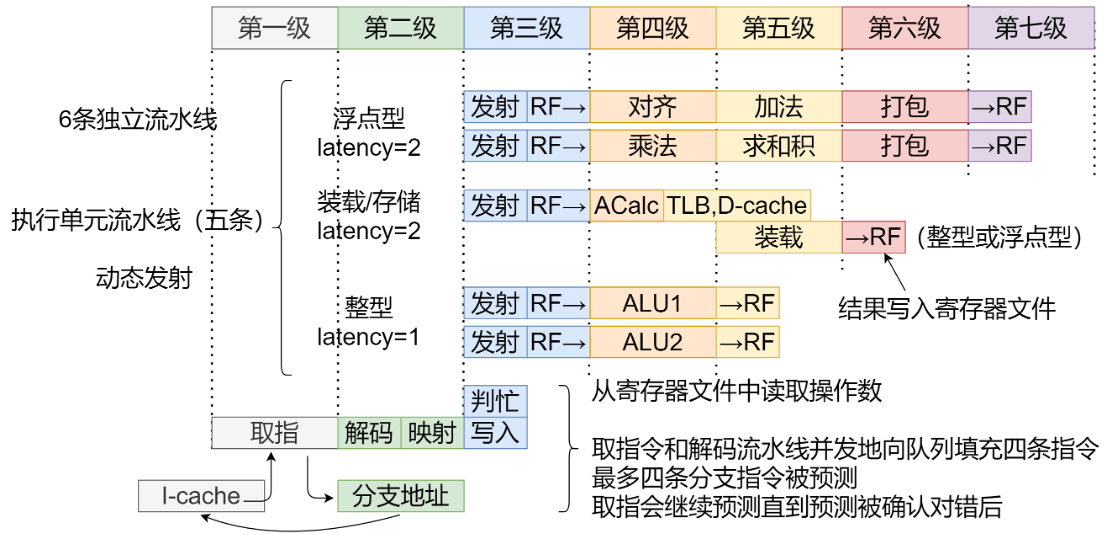
图中“发射”为 Issue Queue
取指级
为了获得更好的性能,处理器需要用比执行更高的带宽来取指和译码,将指令队列保持满载很重要。这样才能提前找到(look ahead)可乱序发射的指令。最终处理器获取到比执行指令数还多的指令,因为在误判分支(mispredicted branch)后会需要放弃部分指令。
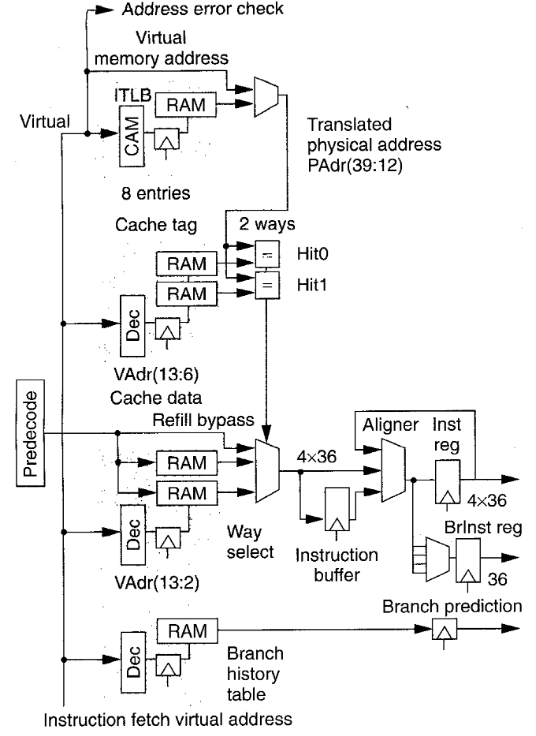
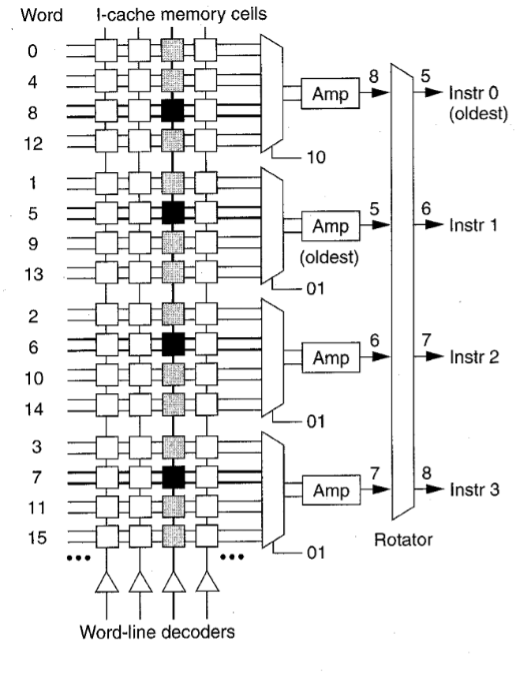
如左图所示,处理器在第1级取指,指令缓存包括地址标记(tag)和数据部分。为实现双向集合关联(Two-way set associativity)。每个部分有两个并行数组。处理器通过将两个标记地址和翻译后的物理地址进行比较,来从正确的一路选择数据。一个8-entry,小的inst TLB是main TLB的翻译事物的子集。
处理器以字对齐(word alignment)的格式在一个16字指令缓存栈(instruction cache line)中并行取指4条指令。
如右图所示,采用一个缓存感知放大器(cache’s sense amplifier)改进方法实现这一特性。每个感知放大器在取指数组中为4比特列宽(as wide as four bit eolumns)。有一个4到1复用选择某一列(表示某一指令)来取指。R10k使用另外的选择信号来对每条未对齐指令进行取指。如果有需要,这些指令会旋转后进行顺序译码,这样的排序减少了相关性逻辑的数量。
通常,除非指令队列或活跃链表已满,处理器将在下一周期译码所有四条指令。没有立即译码的指令保留在一个8字大小的指令缓冲区,从而简化后续取指的时序。
分支单元
分支指令经常出现并必须快速执行,但是,处理器通常要在译码分支之后的几个乃至更多周希之后才能确定分支方向。因此,处理器会沿着预测路径方向消耗和预测取指(fetches instructions speculatively)来完成一个条件分支的预测。
预测使用一个2位算法进行,基于一个512项分支历史表(branch history table)
此表根据分支指令的11:3位地址进行索引,仿真表明对spec92整数程序预测精度为87%。
在 MIPS ISA 架构中,处理器在执行目标地址处的指令之前,立即执行紧跟在跳转或分支指令后面的指令。在一个流水线的标量处理器中,目标指令从高速缓存中读取目标指令时,这种延迟槽指令能够无损耗的执行。这种技术在早起的RISC微处理器能够有效提高分支。然而,对于一个超标量设计,它并没有性能上的优势,但从兼容性考虑,我们仍然为R10k保留了这一特性。
当程序执行了一个跳转或分支,处理器放弃在延迟槽之前取指的任何指令,它把跳转的目标分支地址装载进入PC(程序计数器)。并在一个周期延迟后从缓存获取新指令,这带来一个“分支气泡”周期。在此期间,R10k不进行指令解码。
分支栈
当解码一个分支,处理器将状态保存在一个4项的分支栈中。这包括分支地址,整数和浮点数映射表(map table)的完整拷贝,以及其他控制位。虽然此栈作为一个逻辑实体运行,但物理上它分布在所拷贝信息的附近。
当分支栈满,处理器在遇到下一个分支指令前继续译码,在一个等待的分支解决后,译码才重新开始。
分支验证
即使有些分支即将要执行,处理器也会验证每一个分支预测的确定条件。如果预测不正确,处理器会立即终止所有沿着错误预测路径获取的所有指令,并恢复其分支栈内的状态位。
沿着错误预测路径的取指可能引发不必要的缓存重加载(cache refills)。在这种情况下,指令缓存是非阻塞的。在这些不必要加载完毕后。处理器会沿正确路径取指。由于程序执行会很快选择分支的另一方向,例如循环执行结束,我们并不看重并希望这一加载完成。
对于分支栈的每一项,一个4比特的分支屏蔽位(mask)将在队列和执行流水线中伴随分支的每条指令。此模板知名指令所依赖的是哪个等待(确定)的分支。如果有分支被误预测。处理器将在分支决定反转后,放弃这一指令。一旦R10k验证了一个分支,它会在整个流水线中重置相应的屏蔽位。
译码逻辑
R10k在第2级并行地译码和映射4条指令并在第3级开始时将它们写入合适的指令队列。
当活跃链表或队列已满时则译码停止,但也存在很少的译码受到所译指令类型的限制。主要的例外是整数的乘除指令。计算了结果进入的两个特别的寄存器-HI和LO、此外没有其他指令有多于1个的结果寄存器。对于这些不经常被用到的指令,我们并不增加更多的逻辑;作为替代,它们在活跃链表中占据两个槽位,一旦处理器译码到这样一条指令,在同一周期内,就不会再译码后续指令。(此外也不能再一个周期的第4条指令时译码整数乘除指令。)
指令的读取和修改操作确实控制着寄存器的连续执行。处理器仅仅能够运行这些少数在流水线为空时在内和操作系统模式的指令。这些限制对于处理器的整体性能并没有任何影响。
寄存器映射
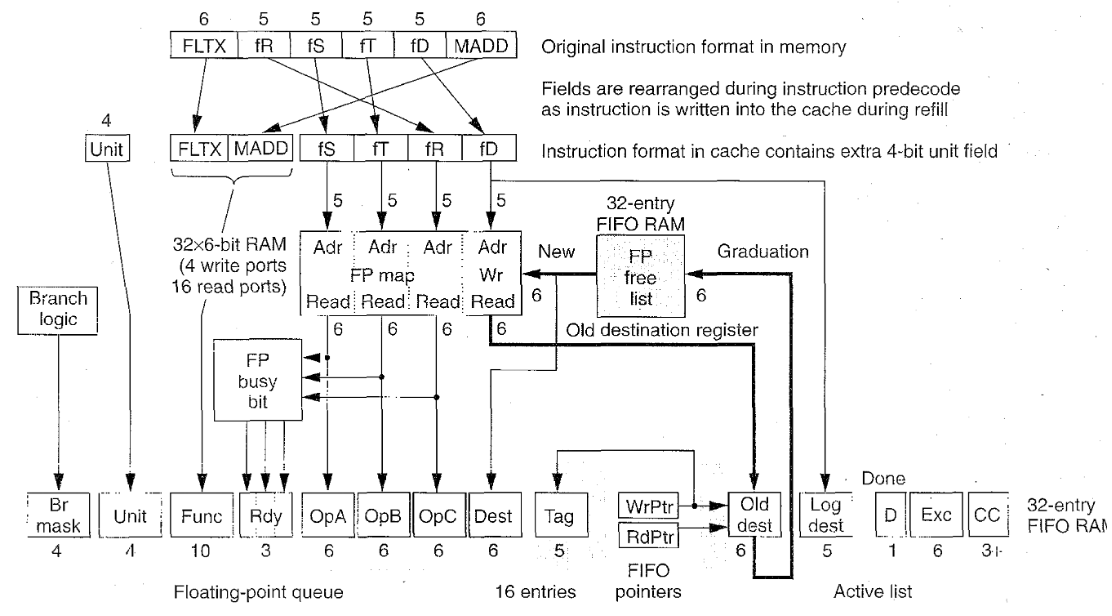 图为寄存器重命名,流水线第二级。R10k在指令预解码期间重新排列字段,因为它在重新填充期间将指令写入高速缓存,高速缓存中的指令格式包含一个额外的4位单元字段。
图为寄存器重命名,流水线第二级。R10k在指令预解码期间重新排列字段,因为它在重新填充期间将指令写入高速缓存,高速缓存中的指令格式包含一个额外的4位单元字段。
上图所示为R10k的寄存器映射硬件,为了错开原有程序顺序执行其指令,处理器必须跟踪其寄存器操作数、内存地址和条件位的相关依赖性。(条件位是由浮点比较指令置位的状态寄存器第8位)为决策寄存器依赖性,R10k使用寄存器重命名,它判断在地址队列中的内存地址的依赖性,在译码时如果发现操作数的值是已知的就将其每个条件位置位,否则,就用浮点比较指令的标记(tag)重命名此条件位,并将随后设置其值。
从程序员的角度来看,指令按程序设定的顺序按序执行,当指令将一个新值加载到目的寄存器,此新值就立即可被后续指令使用。但是,超标量处理器同时执行多条指令,这些指令的计算结果并不能立即被后续指令使用。通常,下一顺序指令必须等待其操作数变为可用,而后续指令的操作数也许已经可用了。
R10k通过乱序执行后续指令来达到更高性能,但这种重排序对程序员是不可见的,乱序执行产生的结果是暂时的,仅当所有前序执行完毕前存在。当指令执行完成毕业其结果也被提交为处理器状态,如果指令发生在例外处理或误预测分支处理中,则当其毕业,其(计算结果)可被放弃。逻辑目标寄存器的原有内容可通过重载原有映射加以访问。
在大多数处理器中并不区分在指令域中引用的逻辑寄存器号和物理寄存器(位于硬件寄存器文件中)。每个指令域直接编址相应的寄存器。但是,我们的重命名策略动态地将逻辑寄存器号映射为物理寄存器号。处理器把每个新的结果写入一个新的物理寄存器中。通过映射,处理器仅需比较物理寄存器号即可判断依赖性。同样,物理寄存器的存在以及逻辑寄存器到物理寄存器之间的映射对于程序员而言也是不可见的。
R10k在解决了对所有以前的指令的依赖后动态执行指令。也就是说,每条指令在其所有操作数被计算出来之前必须等待。然后R10k就可执行这一指令,而不顾虑其原有指令顺序。为正确执行指令,处理器必须确定所有操作数寄存器就绪,因为逻辑寄存器号也许就操作数值而言是模糊的,所以可能会比较复杂。例如,多条指令在流水线中并发执行但指向同一逻辑寄存器则此寄存器不断被加载不同值。
因为物理寄存器存有已提交的(计算结果)值和已完成但尚未毕业指令的临时结果。所以需要比逻辑寄存器数量更多的物理寄存器。当指令流通过流水线时逻辑寄存器可能有一系列值。当指令修改一个寄存器(值)时,处理器就把一个新的物理寄存器指定为目标逻辑寄存器,并将这一指定关系存在寄存器映射表中。当R10k译码一条指令时,就用对应的物理寄存器号去替换其中的逻辑寄存器域(fields)。
在从空闲链表中被指定后,每个物理寄存器只被写入一次,在被写入前,该物理寄存器一直处于忙状态。如果后续指令需要此值,则此指令必须等到有写入值。在物理寄存器被写入后,就处于就绪状态,它的值不再变化 ,当后续指令改变相应逻辑寄存器,它的结果就被写到一个新的物理寄存器,当后续指令毕业,程序不再需要旧的值,则老物理寄存器就被释放后重用。因此,物理寄存器总是具有不确定的值,
共有33个(编号1-31,Hi和Lo)逻辑和64个物理整数寄存器(设有整数寄存器0,用零操作数域来指定零值,用零目的域指明未存储值),有32个(编号0-31)和64个物理浮点寄存器。
寄存器映射表
处理器独立地重命名整数和浮点寄存器,用分别的寄存器文件存储。整数和浮点映射表包含了当前的逻辑到物理寄存器指定关系。处理器使用5位指令域选择逻辑寄存器。在相应寄存器文件中的6位地址指向物理寄存器。
浮点表在一个32*6比特的多端口RAM中映射寄存器到。(32是逻辑寄存器的个数,6比特为物理地址)。
整数表在一个33*6比特的多端口RAM中映射寄存器到(Hi和Lo寄存器有特别的访问逻辑,隐含在整数乘、除指令的目的寄存器中)。
映射表有16个读端口和4个写端口,可并行映射4条指令。每条指令从映射表中读取3个操作数寄存器和1个目的寄存器。处理器把当前的操作数(寄存器)映射和新的目的(寄存器)映射写入指令队列。而活跃链表保存之前的目的(寄存器)映射。
R10k使用一个24个5位比较器来并行地检测译码中的4条指令依赖性,这些比较器控制旁路复用开关(control bypass multiplexers),用空闲链表中的新指定来替换有依赖的操作数。
空闲链表
整数和浮点空闲链表包含了当前未指定的物理寄存器链表。由于处理器并行译码和毕业最多四条指令。这些链表由4个并行,深度为8的循环FIFO(先进先出)链表组成。
活跃链表
活跃链表记录了在处理器中当前活跃的所有指令,在处理器对其译码时将每条指令增入此表中。当指令毕业时,从链表中移除该指令,或当发生分支误预测或产生异常(exception)时引发指令被放弃。因为最大活跃指令数为32,则活跃链表由4个并行,深度为8的循环FIFO链表组成。
每条指令用一个5bit的标识来识别,也就是它们在活跃链表中的地址,当某执行单元执行完一条指令,就把指令标识发回活跃链表,用来置位其执行完毕比特位。
活跃链表包含有每条指令的逻辑目的寄存器号以及其旧有的物理寄存器号,在指令毕业时确认其新的映射。这样旧有的物理寄存器就被返回到空闲链表中共后续使用。
但当发生异常时,后续指令就不会毕业。此时处理器就从活跃链表中恢复原有的映射。R10k每周期回复4条已映射指令---以相反的顺序。以防同一逻辑寄存器被重命名两次。虽然这比恢复一个分支要慢,但是误判分支要比异常常见的多。处理器通过恢复它们的读指针把新的物理寄存器返回到空闲链表。
忙比特表
对每个物理寄存器而言,整数和浮点忙比特表包含了1比特表明此寄存器现存是否是一个有效值。每个表是一个64*1比特的多端口RAM。当相应的物理寄存器离开空闲链表时,表中对应的忙比特置位。当某执行单元向物理寄存器中写入一个值时,忙比特被重置。12个读端口为每四条新译码的指令确定其三个操作数寄存器的状态。队列使用其余三个端口应对特定情况指令。例如在整数和浮点寄存器文件间移动数据。
指令队列
R10k将除跳转指令和无操作NOP指令外的每条译码后指令根据类型放入三个指令队列中的一个,只要还有空间,队列可以接受任意新指令组合。
芯片的周期时间约束了我们的队列设计。例如:我们对每条发射指令设计了两个寄存器文件读端口,以避免任意延迟和操作数总线复用(to avoid delays arbitrating and multiplexing operand buses)。
整型队列
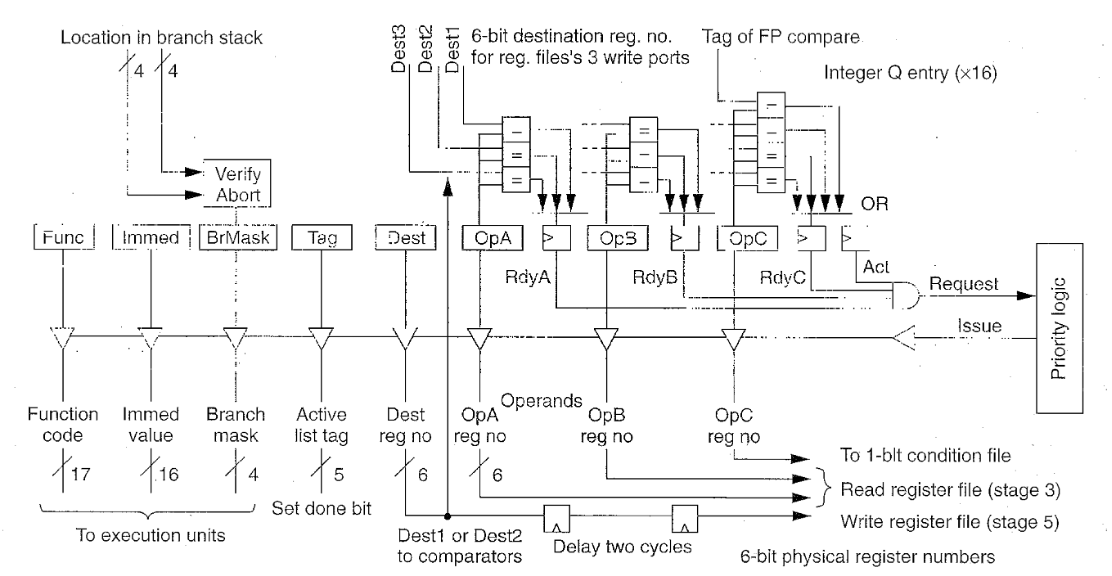 整型指令队列,仅展现了一个发送端口。队列能够同时发出两条指令。
整型指令队列,仅展现了一个发送端口。队列能够同时发出两条指令。
整数队列共有16项,没有特别的顺序安排,当整数指令译码时就分配一项。当指令被发射到一个算术逻辑单元时队列就释放该项。
只有某个算术逻辑单元可以执行的指令具有此算术逻辑单元的优先权。因此,分支和位移指令有ALU1的优先权。整数和除指令有ALU2的优先权。为了简化,队列中的位置而不是指令的年龄决定其发射的优先权 。但是,一个轮转请求电路会提升年长指令对ALU2的优先权。
图为整数指令队列中一项的内容。包括:三个含有物理寄存器号的操作数选择域。每个域有一个根据忙比特表初始化的就绪比特位。队列将对应于整数寄存器文件写端口的三个目的选择与每个选择进行比较。任何的比较成功就将相应就绪比特置位。当所有操作数就绪后队列将指令发射至执行单元。
操作数C要么包含一个条件位值或者包含一个可将此值置位的浮点比较指令的标识。总之,每16个项包括10个6比特比较器。
队列向执行单元发射功能码和立即数值,分支掩码决定由于误预测分支此指令是否放弃。在处理器完成一条指令后标识在活跃链表中置位完成比特位。
整数指令单周期时延将队列时序和逻辑复杂化。在一个周期内,队列必须发射两条指令,检查操作数就绪情况。并请求相关指令,下图说明了这一过程。
为了实现2周期加载时延,对整数装载结果有依赖的指令必须进行试探性发射,假设此加载会成功完成。依赖性指令在它执行的前一周期被发射。同时进行加载读数据缓存。如果因为缓存缺失或一个依赖加载失败。必须放弃对依赖性指令的发射,图7b说明了这一过程。
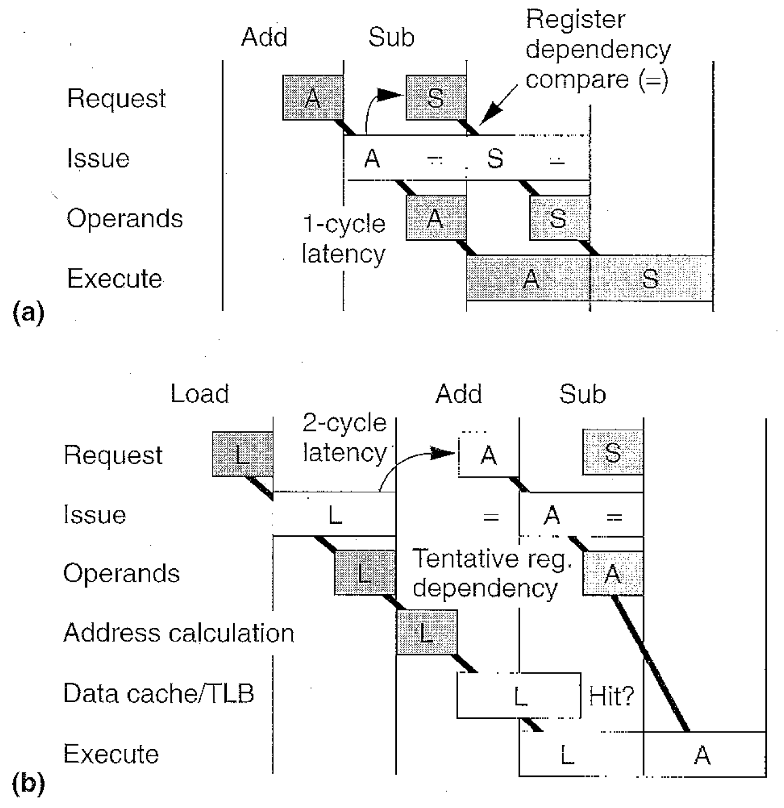 释放寄存器依赖整型队列(a)和指令的试探性发送依赖于早期装载的指令(b)
释放寄存器依赖整型队列(a)和指令的试探性发送依赖于早期装载的指令(b)
地址队列
地址队列共有16项,不同于其他两个队列,它使用先进先出的循环链表来保持原始程序的指令顺序。在处理器译码一条加载或存储指令时分配一项并在指令毕业后移除该项。队列使用指令顺序来判断内存依赖并将最年长的指令赋予优先级。
当处理器恢复一个误预测分支时,地址队列将从该分支开始后所有译码后的指令,以恢复写入指针的方式从队尾开始进行移除。队列使用和整数队列相类似(不同之处在于这里的逻辑只包含两个寄存器操作数)的逻辑向地址计算单元发射指令。
地址队列比其他队列更复杂,当有内存地址依赖或数据缓存缺失时,加载或存储指令可能需要重试。
两个16*16位的矩阵用以跟踪内存访问之间的依赖性。行、列对应于队列中的项。第一个矩阵通过跟踪哪些项访问同样的缓存集合(虚拟地址13:5)来避免不必要的缓存颠簸(cache thrashing)集合(行、列)的任一个方向都可被乱序执行的指令所用。但如有两个或更多队列项在同一缓存集合地址不同线路,另一个方式是保存访问这一集合的最年长项。第二个矩阵跟踪作为等待加载相同字节指令的存储指令,它通过比较双字地址和8位地址掩码来判定是否相同。
当有外部接口访问数据缓存,处理器会将其索引与队列中所有等待项进行比较,若加载项与重载入(refill)地址一致,则将重载入数据直接传递给目的寄存器。若某项匹配了一个非法命令,则该项状态被清除。
虽然地址队列不接指令的原有顺序执行加载和存储,但它维持顺序内存一致性。然而,外部接口可能会违反这一一致性,在加载指令毕业前,当缓存线(cache line)被用来加载一个寄存器之后,通过禁止(invalidation)此缓存线形成。在此情形下队列对此加载指令建立软异常(soft exception)。异常会更新(flushes)流水线并放弃指令以及其后所有的指令,这样处理器就不会使用过时(stale)的数据。随后,处理器只需从被放弃的加载指令开始恢复正常执行,而不是继续执行异常处理(这一策略保证了向前推进,因为最年长的指令在完成后就立即毕业了)。
存储指令需要地址队列和活跃链表之间的特定协调。队列必须在存储指令毕业时,精确的写入数据缓存。
MIPS架构使用加载连线(Load-Link,LL)和条件存储(Store-Conditional,SC)指令对来模拟内存原子操作。由于它们并不需要对内存进行加锁访问,这些指令并不增加系统设计复杂性。典型的顺序是:处理器用LL指令加载一个值,测试并修改之,之后用SC指令条件写入储存。SC指令仅在此值没有冲突并且连线字(Link word)仍在缓存中时写入内存。处理器在结果寄存器中加载1或0来表明内存写是否完成。
浮点型队列
浮点队列共有16项,与整数队列非常类似,但不包括立即数值。由于额外的线路时延(writing delay)浮点加载有三个周期延迟。
寄存器文件
整数和浮点数寄存器文件各包含有64个物理寄存器。执行单元直接从寄存器文件中读取操作数,并直接写回结果。结果可能会直通写入操作数寄存器,短路掉寄存器文件,但是并没有分立的结构如保留站或重排序缓冲区存在于宽数据路径上。
整数寄存器文件有7个读端口和3个写端口。每个算逻单元各有两个独有的读和一个独有的写端口。地址计算单元有两个独有的读端口。第七个读端口负责处理存储跳转寄存器和移至浮点指令。第三个写端口负责处理加载分支和连线(branch-and-link)和从浮点移出指令。
另有 64-word * 1-bit 的条件文件指示对应物理寄存器的值是否非零。其三个写端口和整数寄存器文件一并操作。两个读端口使整数与浮点条件移动指令不需要访问整个寄存器仅测试单个比特(就可知道是否合法)。此文件比寄存器文件使用更小面积(比寄存器文件少2个额外的读端口)。
浮点寄存器文件有5个读和3个写端口。加法器和乘法器各有两个独有的读端口和一个独有的写端口。第5个读端口处理存储和移动指令。第3个写端口处理加载和移动指令。
整型执行单元
每个周期中,整数队列向整数执行单元发射两条指令。
整型 ALUs
两个整型ALU各含有一个64位加法器和一个逻辑单元。此外,ALU1有一个64位位移器和条件分支逻辑。ALU2有整数乘法器数组和整数除法逻辑。下图为ALU1框图。各ALU有两个从寄存器文件加载的64位操作数寄存器。为满足单周期时延,三个寄存器文件的写端口直通(bypass)到操作数寄存器。整数队列同时控制这两个ALU,提供操作码、立即数和 bypass 控制等。
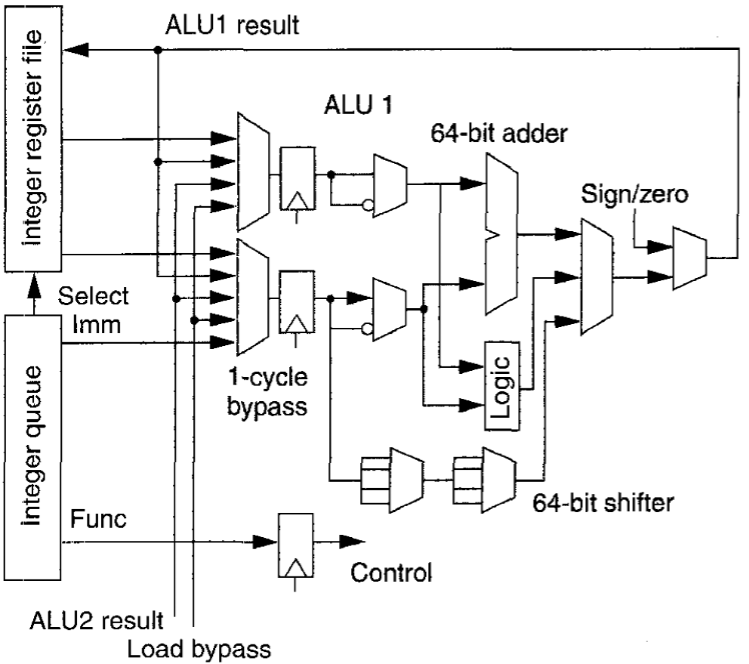
整型乘法和除法
ALU2不断计算整数乘/除。如前所述,这些指令有两个目的寄存器,Hi和Lo。对乘法指令,Hi和Lo存放双精度乘数的高位和低位;对于除法指令则包含余数和商。
ALU2使用Booth算法计算整数乘法和对乘数的每两位产生一部分乘积。算法每周期产生并累加4个部分乘积。ALU2指令发射后的第一个周期就处于忙状态,并在最后两个周期存入结果。
为计算整数除法,ALU2使用每周期产生1位的非恢复算法(nonrestoring algorithm)。ALU2在整个操作中处于忙状态。
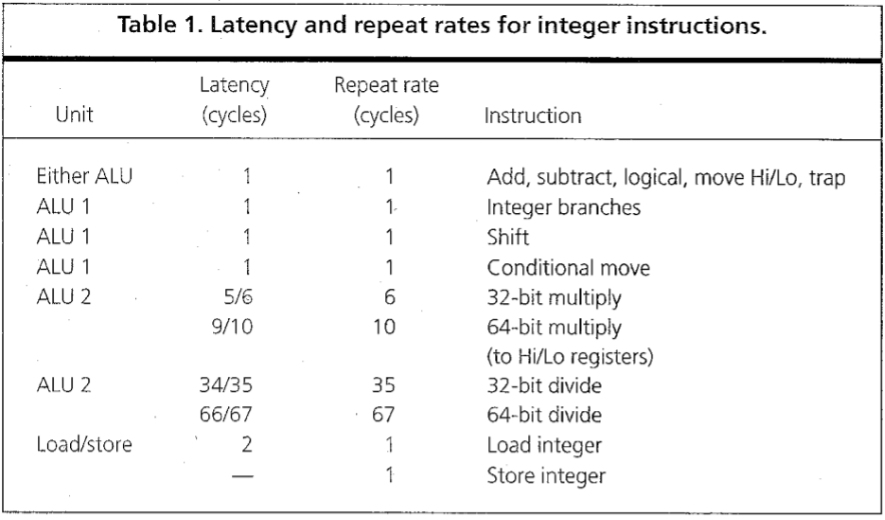
下表列出了普通整数指令的延迟和重复率。
浮点型执行单元
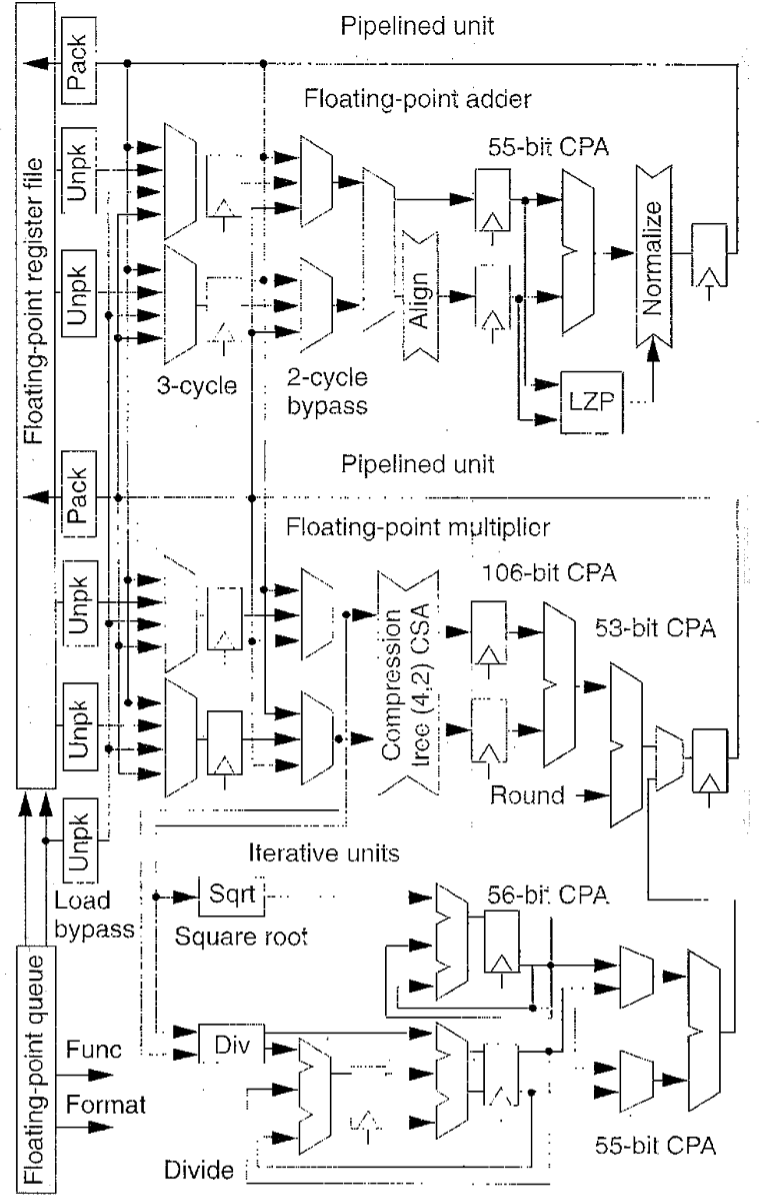 如图所示为浮点执行单元的尾数数据路径(指数逻辑没有画出)。加法器和乘法器有三级流水线。两个单元都是具有单周期重复率的全流水线结果。计算结果可以旁路(bypass)寄存器文件,具有两个或三个周期延迟。所有的浮点操作数将从浮点队列中发出。
如图所示为浮点执行单元的尾数数据路径(指数逻辑没有画出)。加法器和乘法器有三级流水线。两个单元都是具有单周期重复率的全流水线结果。计算结果可以旁路(bypass)寄存器文件,具有两个或三个周期延迟。所有的浮点操作数将从浮点队列中发出。
浮点加法器
加法器完成浮点的加、减、比较以及转换操作。第一阶段进行操作数指数减法,选择较大的操作数,并在一个55位右移移位器中将较小的尾数对齐。第二阶段根据操作要求加减尾数,并对操作数置(正负)标志。
大数量级的加法产生进位,需要进行一位右移来进行位置归一化。从概念上来讲,处理器需要在结果产生后才对其右移,为了避免更多的时延,用两个进位链加法器(Carry-chain adder)同时产生+1和+2两种累加。如果操作数需要右移来位置归一化,处理器会选择+2链。
另一方面,一个大数量级的减法可能引起大量的回撤,在结果中产生高阶零。首零预测电路判别减法会产生多少个高阶零。它的输出控制着一个55位的左移位器来归一化结果。
浮点乘法器
乘法器在全双精度数组中执行浮点乘法。因为与加法器相比较空闲,因此它还执行移位或条件移动操作的复用。
在首个周期,单元对乘数的53位尾数进行Booth算法编码,用于选择27个部分乘积(采用Booth编码时,乘数的每2位需对应一部分乘积)。压缩树采用一个4×2数组来进位保存加法器。加法器将4位求和为两个和与进位输出。在第二周期,使用一个106位进位传播加法器组合出求和结果及其进位值。最终由53位加法器轮转获得结果。
浮点除法和平方根
两个迭代单元分别用来执行浮点除法和平方根。每个单元均使用SRT算法在每个迭代级上产生2位结果。除法单元在每个周期内级联两个阶段,每个周期生成4比特。
这些单元和乘法器共享寄存器文件端口,每次操作独占2个周期。第一周期发射指令并从寄存器文件中读出操作数。操作结束后,使用第二个周期来向寄存器文件写回结果。
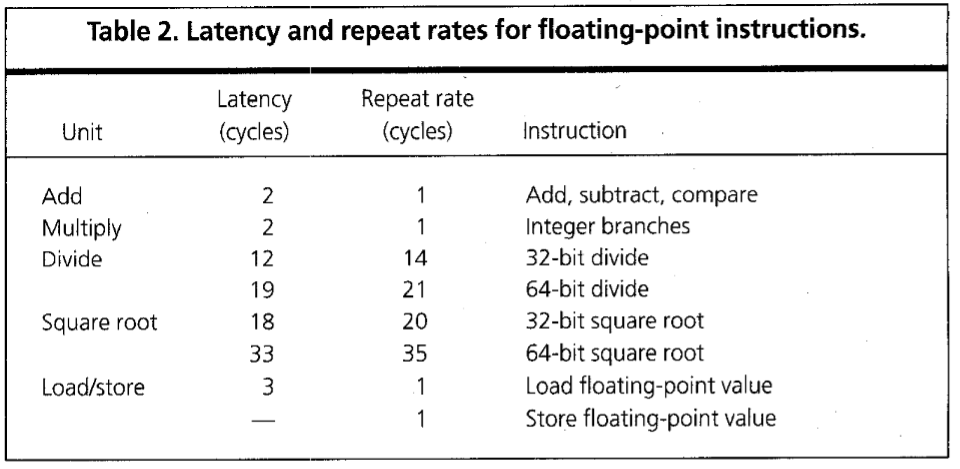
表2为普通浮点指令的延迟和重复率。
存储器层次架构
存储访问延迟对处理器性能有重大影响。为了高效运行大程序,R10k采用两级组相联高速缓存构成非阻塞存储器层次结构。芯片上的一级指令和数据缓存并发执行,提供低延迟和高带宽支持。芯片也控制一个大型外部二级缓存,所有缓存使用最近最少使用替换算法。
指令和数据一级缓存使用虚拟地址索引和物理地址标志。为减小延迟,处理器在其TLB进行地址翻译时可以并行地访问各个等级缓存。因为每个缓存通路都有16Kb大小(最小虚拟页的4倍大),两个虚拟索引位和物理地址标志位大小可能不同。此技术是为了简化高速缓存的设计,只要程序使用一致的虚索引来指向相同页就会工作正常。处理器将这两个虚地址位作为二级缓存标志位的一部分保存下来。二级缓存控制器检测可能的冲突并确保每路缓存只保留单个副本。
Load/Store 单元
下图为加载/存储单元及数据缓存的框图。地址队列加载、读取指令到地址计算单元和数据缓存中。在缓存空闲时,装载指令能够同时访问TLB、缓存标志数组和缓存数据数组。这些并行访问引发两个周期的加载延迟。
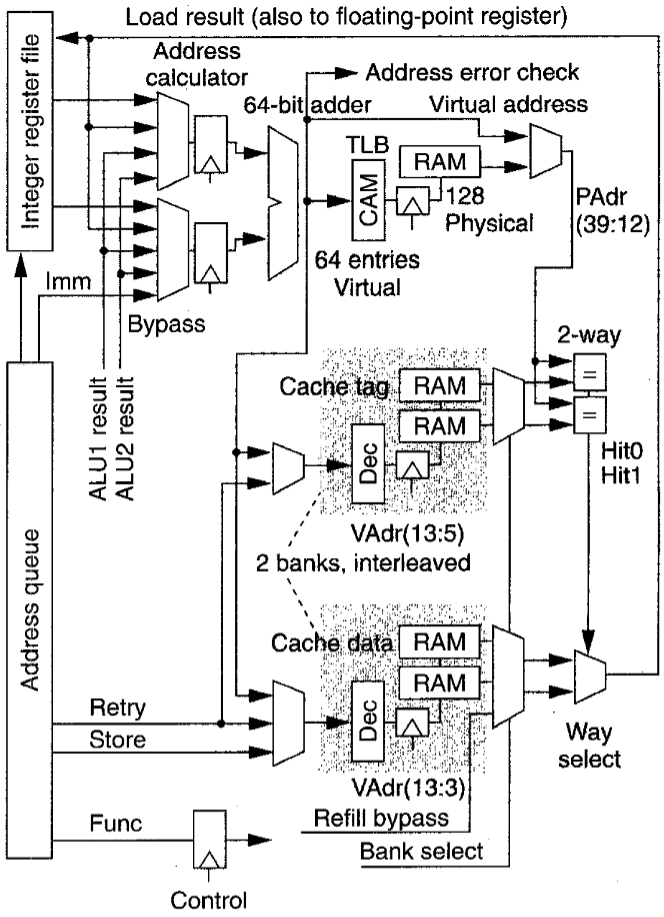
地址计算
R10k使用两个64位寄存器或者一个寄存器和16位立即数域(immediate field)来计算虚拟内存地址。这导致了ALU或数据缓存器绕过了寄存器文件到操作数寄存器中。此时TLB会将这些虚拟地址转换成为物理地址。
内存地址翻译(TLB)
MIPS-4架构定义64位寻址。实际实现时为了减少TLB和缓存数组的代价,减小了最大地址位宽。R10k全关联翻译备寻缓冲区(Translation Look-aside Buffer, TLB)将44位虚地址翻译为40位物理地址。TLB与R4000中的相类似,但我们将其增加到64页。每项映射严格虚页并独立在4K和16M字节间选择4的任意次方的页大小。TLB包括了能够比较虚拟地址的内容可寻址处理器(CAM部分)和一个包含相应物理地址的RAM部分。
L1 I-cache
32K字节指令缓存包含了8192个指令字。每个都被预解码成36比特格式。相比较用原格式,处理器可以更快地解码这一扩展格式。其中,额外的四比特指明了执行此指令的功能单元。预解码在每条指令的操作数和目的选择域的相同位置上对它们进行了重新排列。最后,处理器修改一些操作码的整数或浮点目的寄存器,一次来简化译码。(参考上面cache的组织结构图)
L1 D-cache
数据缓存为了增加带宽,交织了两个16K字节块(Bank),处理器在下面四条请求流水线上为每个块独立地分配标识和数据数组。
- 外部接口(refill数据,interventions等)
- 为新计算的地址进行标记(Tag)检查
- retrying a load指令
- graduating a store指令
为简化接口并减少所需要的缓冲区数量,外部接口对其需要的数组设置优先权。接口请求要在缓存读或写两个周期之前完成,这样处理器可以在其多个流水线间分配重命名资源。
数据缓存为 8-word line size,这是一个方便的妥协。更大的字长可以减少标签RAM数组面积,适度降低未命中率,但在填充高速缓存时会消耗更多的带宽。设置成八字行大小,二级缓存带宽就可支持3或4个重叠的重载入。
每个数据缓存块都包括两个逻辑数组,支持两路集合关联。如下图所示,不同于一般安排,缓存路径在这两个数据间切换以有效支持不同宽度访问。
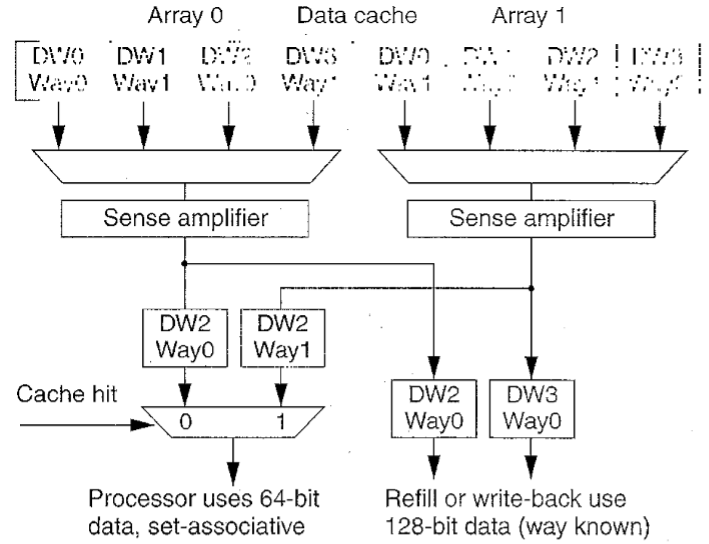 处理器从两个缓存路径同时读取一个双字。因其并行检查缓存标识,就可以随后从正确的一路选择数据,从错误的路径得到的双字被丢弃。通过并行访问两个双字,外部接口重载入或写入四字内容。由于处理器预知正确的缓存路径,上述操作是可行的。
处理器从两个缓存路径同时读取一个双字。因其并行检查缓存标识,就可以随后从正确的一路选择数据,从错误的路径得到的双字被丢弃。通过并行访问两个双字,外部接口重载入或写入四字内容。由于处理器预知正确的缓存路径,上述操作是可行的。
这一安排充分利用缓存感知放大器,因为每个放大器有四列内存单元,所以每个放大器总包含一个4选1复用器,我们通过改变选择逻辑实现这一功能。
L2 Cache
我们使用外部同步静态RAM芯片来实现512K至16M字节大小的两路集合关联二级缓存。根据系统要求,用户可以配置二级缓存行为16或32字。
集合关联降低缺失冲突并增加了可预测性,但是对外部缓存通常需要特别RAM或更多的接口引脚。然而,R10k使用标准同步SRAM和仅一个额外的地址引脚来实现两路虚拟组关联缓存。
下图说明了缓存重载入是如何流水线化的。单组RAM包含了两路缓存路径,用片内一个bit数组来跟踪是哪个缓存集合的哪一个路径在最近使用过缓存。当发生一级缓存缺失,从这一路径的二级缓存中读入两个四字。在第一个四字读时同时读标识。下一个四字读时,通过翻转额外的地址引脚来读另一路的标识。
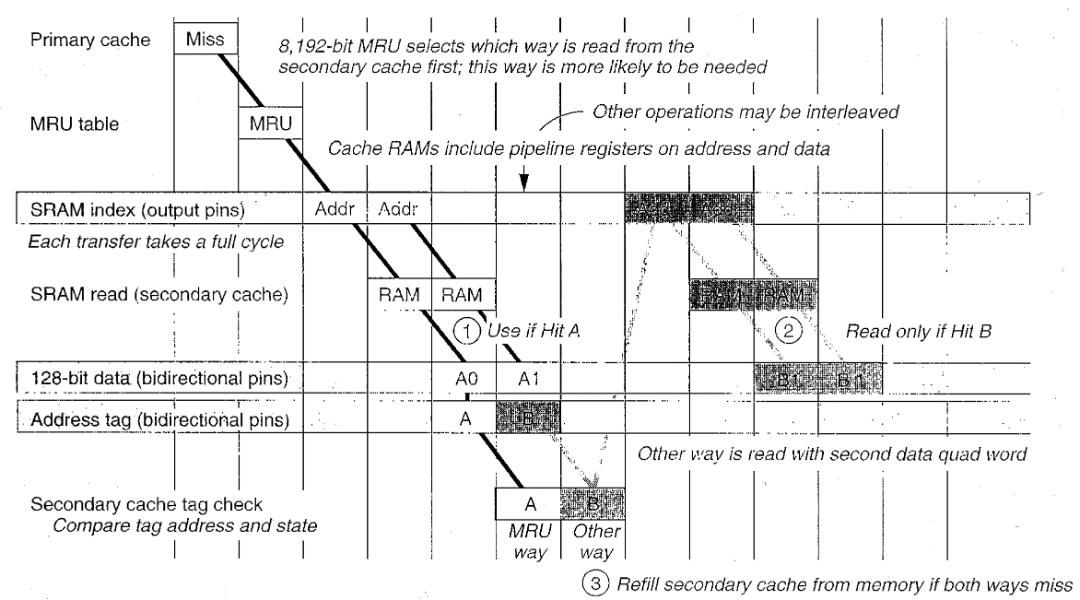 从组相连的二级缓存中填充数据。在这个例子中,二级缓存的时钟同处理器内部时钟一致。实际中,二级缓存时钟慢一些。
从组相连的二级缓存中填充数据。在这个例子中,二级缓存的时钟同处理器内部时钟一致。实际中,二级缓存时钟慢一些。
会发生三种情况:如果第一路命中,则数据立即生效;如另一路命中,处理器就再读一次二级缓存;如两路都未命中,则处理器需要从内存中重载入二级缓存。
大的外部缓存需要使用错误矫正码来保证数据完整性。R10k为每四字数据存储一个9位ECC码和一个校验位。校验位能被快速查验并阻止坏数据的使用,进而减少时延。在处理器检查到一个可被校正的错误时,它将从一个两周期的校正流水线上重读。
我们可为所有读取配置接口。使用这个校正流水线虽然增加了延迟,但在发生可校正错误时,它使得冗余的锁步处理器可以保存同步。
系统接口
R10k使用地址/数据复用的64位事务分隔系统总线与外部世界进行通讯。总线可最多将4个R10k芯片直接连接成集群,并叠加最多八个读请求。
系统接口投入巨大资源来支持并发和乱序执行。高速缓存填充在高达四个来自二级缓存或主存的未付读请求下也是无锁的。这些都是有未命中处理表来控制的。
四个未完成的读请求地址保存在缓冲区中。由这些请求返回的内存数据被存入一个四项达到缓冲区中,因而可以以任何速率和任何顺序接收。发生缓冲区最多保留5个将被写回内存的“受害者”块。当总线连接的二级缓存无效时,缓存需要写入第五条目中。
一个八项的集群缓冲区跟踪系统总线上的所有未完成操作。它通过询问,在必须时禁止缓存线来确保缓存一致性。
非缓存的加载和存储操作指令,当它们成为流水线最“年长”指令时就要顺序执行。处理器经常使用非缓存写来对图形或者其他外设进行写操作。此序列典型地由大量顺序或一致的地址访问组成。未缓存的缓冲区自动地归集为32字块来减少总线带宽。
时钟
片内的锁项环(PLL, Phase-locked loop)同步产生所有时序,包括外部系统接口时钟。从系统设计和升级灵活性考虑,使用独立的时钟分频器,让用户选择5个二级缓存和7个系统接口时钟频率。为了提供更多的选择,我们以两倍于流水线时钟的PLL时钟振荡器频率产生这些时钟。流水线运行在200MHZ,PLL运行在400MHZ。用户可以配置系统接口运行在200、133、100、80、66.7、57或者54MHZ。此外,用户可以单独配置二级缓存运行在200到66.7MHZ。
输出驱动
四组缓冲区驱动芯片的输出引脚。用户可以独立配置每组引脚遵循低电压CMOS或HSTL标准,为每组进行的缓冲区设计有特定的硬件特性。
下图说明这些缓冲区是如何互连的。系统接口缓冲区有另外的开放通道下拉三极管,提供驱动HSTL2类多路总线的额外电路。
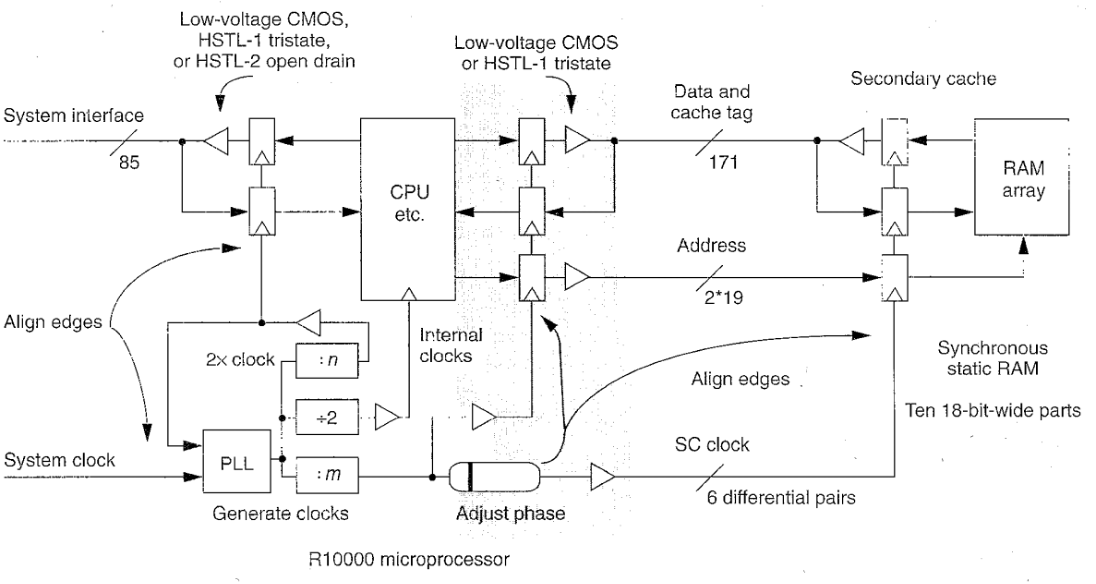
我们设计二级缓存数据缓冲区来减少在交换时的叠加电流尖峰。因为这些同时交换的信号有近200个。
缓存地址缓冲区使用标志极电晶体管来快速驱动多个分布式负载。缓存时钟缓冲区用最小输出延迟驱动低阻差分信号。一个低时延抖动元素精确地对齐这些时钟。这一时延被静态地配置,以调整印刷电路版时钟线路的传播延迟,以时钟上升沿和处理器内部时钟信号同时到达缓存。
测试特性
微处理器芯片必须易于进行高故障覆盖的测试才能进行有经济性的生产。R10k用10个128位线性反馈移位存储器来观察内部信号。内部测试点将芯片划分为三个可完全观测的部分。
寄存器具有分立的结构并不影响处理器的逻辑或对被观测信号增加显著的负载。它们使用处理器时钟,避免了任何特有的时钟需求,确保同步行为,这对调试或生产性测试很有用。
性能
我们现在在SGI挑战服务器上装载200MHz的R10k微处理器,而其他几个供应商也会因为R10k的特别设计开始在系统中使用R10k处理器。我们规划了如下的一个系统——200MHZ的R10k微处理器,4M字节二级缓存,100MHZ系统接口总线和180ns存储延迟。系统性能表现如下:
- SPEC95int(峰值)9
- SPEC95fp(峰值)19
上述特性是我们根据一个R1000实际运行系统推算出来的。实际系统的处理器、缓存、内存速率都按比例较基准测试慢一些。我们用较早版本的 MIPS Mongoose 编译器进行编译。