数据精度格式
本页面系统整理 AI 训练、推理、HPC 和工程选型场景中的各种数据精度格式,帮助您理解它们的差异、联系、应用场景和硬件支持情况。
核心概念
位宽 (Bit Width)
表示数据的总位数,决定了存储和带宽需求。常见的有 4、8、16、32、64 位。
精度 (Precision)
表示数据能够表示的最小差异,由尾数位数决定。精度越高,数值越细腻。
动态范围 (Dynamic Range)
表示能够表示的最大值和最小值之间的范围,由指数位数决定。
混合精度 (Mixed Precision)
在训练或推理中同时使用多种精度格式,平衡性能、内存和精度需求。
指数位 (Exponent)
决定数值的动态范围。指数位越多,能表示的最大值和最小值范围越大。
尾数位 (Mantissa)
决定数值的精度。尾数位越多,能表示的数值越精细。
量化 (Quantization)
将高精度数值映射到低精度格式的过程,通常用于模型压缩和加速推理。
IEEE 754
国际标准浮点数格式规范,定义了 FP16、FP32、FP64 等标准格式。
格式详情
硬件支持
| 格式 | NVIDIA Volta | NVIDIA Turing | NVIDIA Ampere | NVIDIA Hopper | NVIDIA Blackwell | AMD CDNA 2 | AMD CDNA 3 | Intel Xe | Intel Gaudi | Google TPU v3 | Google TPU v4 | Google TPU v5e | Google TPU v5p | 华为 昇腾 910 | 华为 昇腾 910B | 华为 昇腾 910C |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FP64 | ||||||||||||||||
| FP32 | ||||||||||||||||
| TF32 | ||||||||||||||||
| BF16 | ||||||||||||||||
| FP16 | ||||||||||||||||
| FP8 E4M3 | ||||||||||||||||
| FP8 E5M2 | ||||||||||||||||
| INT8 | ||||||||||||||||
| INT4 |
Fused FP8 4-Way Dot Product
这篇论文提出了两种 FP8 融合 4 路点积微架构,支持缩放因子和 FP32 累加,全程只做一次舍入,在面积和功耗上做了精细权衡。
为什么需要 FP8 点积
GEMM 是瓶颈
AI 训练和推理中,矩阵乘法 (GEMM) 占据绝大部分计算量,其核心就是大量的点积运算。
FP8 是趋势
从 FP32 → FP16/BF16 → FP8,精度逐步降低但吞吐翻倍。FP8 已在 H100 等硬件上获得原生支持。
融合 = 更精确
融合操作将乘法和累加合并,中间不做舍入,只在最终结果做一次舍入,误差显著降低。
缩放因子不可少
FP8 动态范围有限,需要 scaling factor 调整数值范围,论文支持 7-bit 缩放因子。
核心思路
输入与输出
- op1, op2: 两个 32-bit 操作数,各含 4 个 FP8 值
- acc: FP32 累加器
- sf: 7-bit 缩放因子
- FP32 结果 = rnd(2-sf × SoP + acc)
- 其中 SoP = Σ op1[i] × op2[i]
中间格式统一
E4M3 和 E5M2 先统一转换为 9-bit 中间格式(5 位指数 + 3 位尾数,excess-15 偏置),再进入后续计算。E5M2 只需末位补 0,E4M3 需要指数扩展加 8。
两种微架构
设计 A: Late Accumulation (LA)
复用 FP32 加法器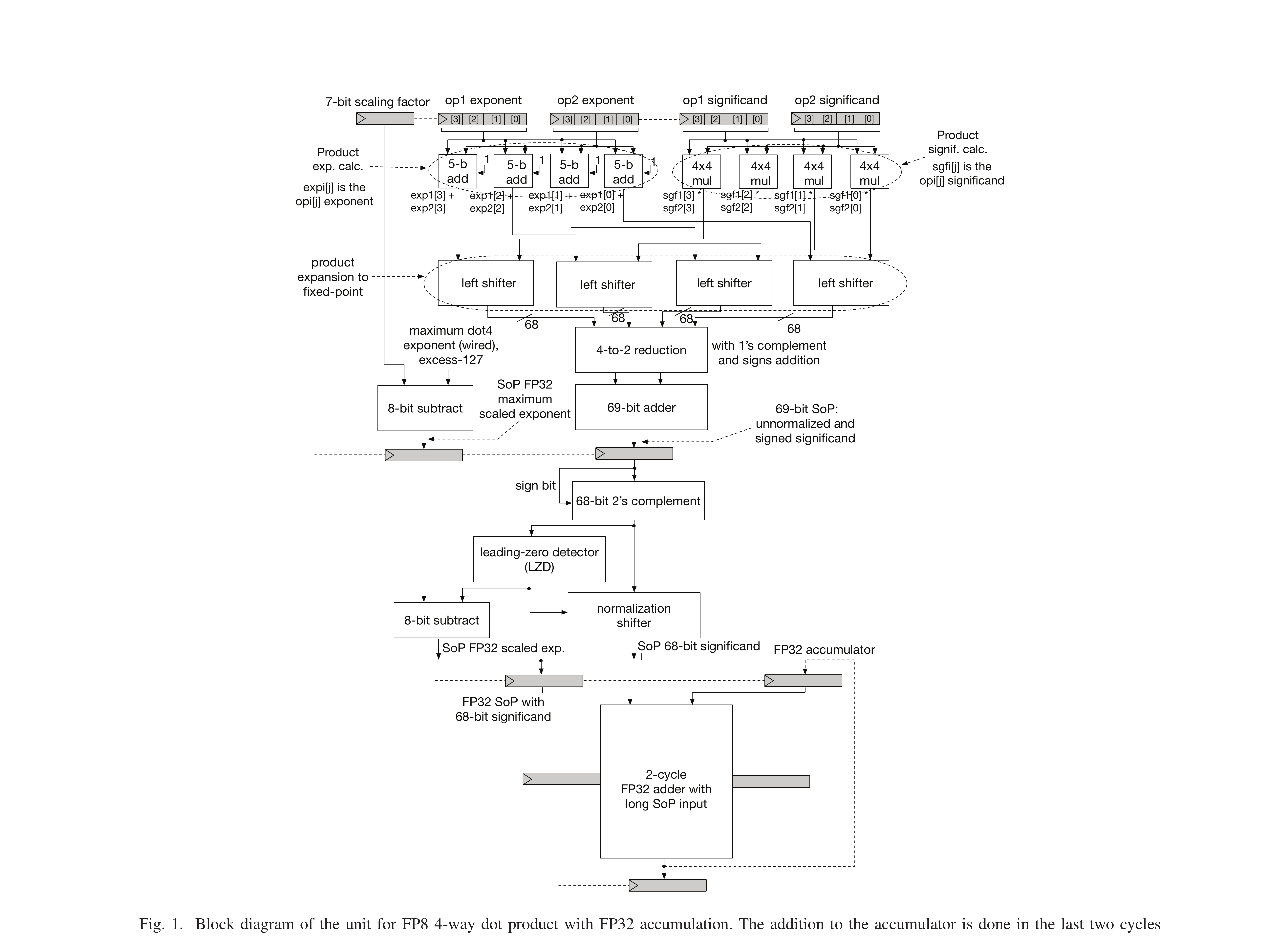
适合高性能 CPU,增量成本低(只增加 SoP 逻辑 572 sq.μm + 改造 FADD32 561 sq.μm)
设计 B: Early Accumulation (EA)
独立数据通路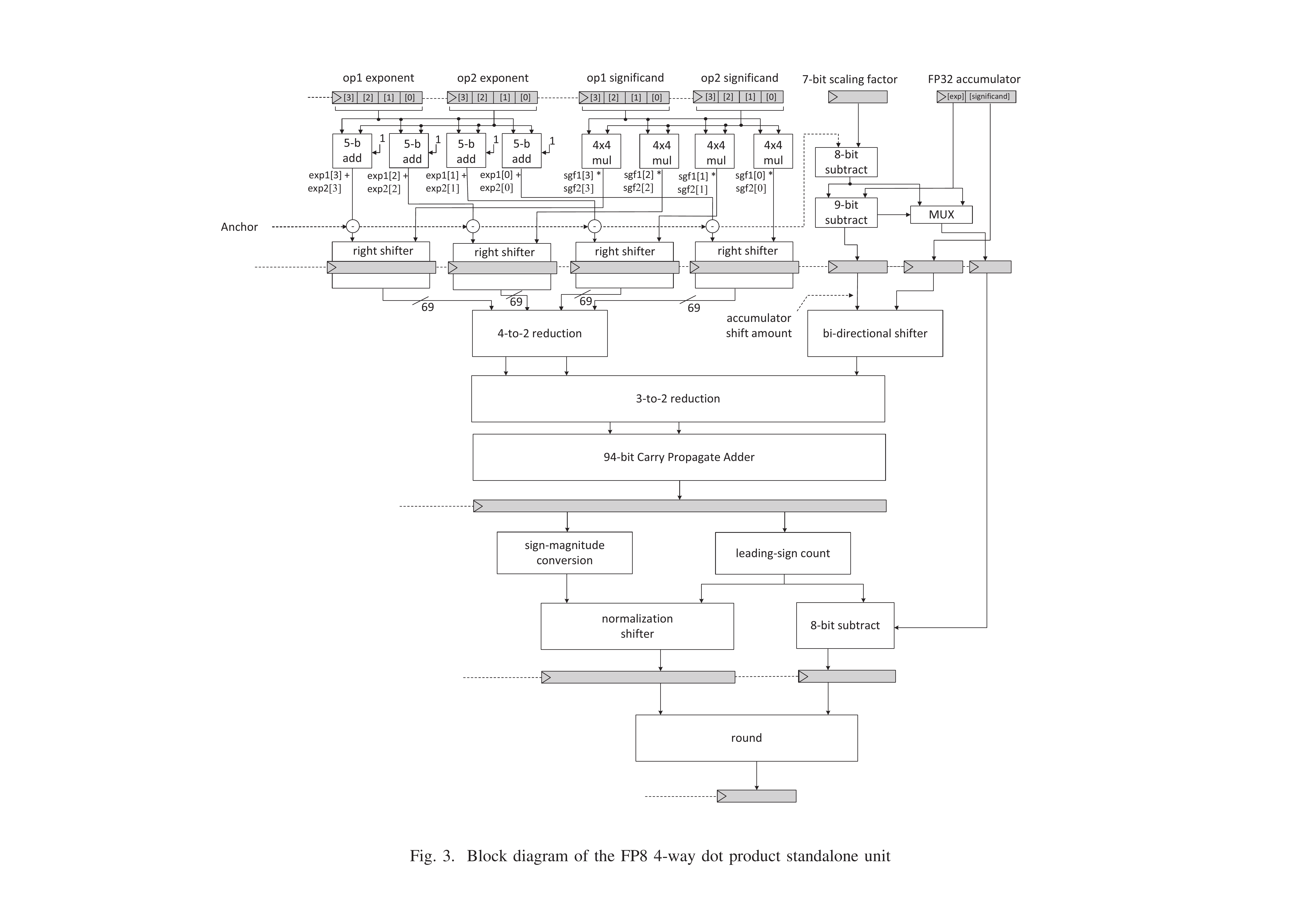
适合专用加速器,总面积更小(674 vs 1133),但无法复用为通用 FP32 加法器
关键设计技巧
避免对齐移位
传统点积需要把每个乘积对齐到最大指数,代价是多个减法器 + 移位器。LA 用最大乘积指数、EA 用 Anchor 作为参考点,避免了逐个对齐。
Anchor 机制 (EA)
anchor = max(P_exp) + ceil(log2(N)) + 1。所有乘积都右移到 Anchor 位置对齐,累加器也只需一个双向移位器。
单次舍入
中间结果全部保持完整精度(68-bit 或 94-bit 宽),只在最终写回 FP32 时做一次 RNE 舍入,误差最小。
可扩展为 DOT2 × 2
两种设计都可以直接扩展为 2 个并行的 2-way 点积 + FP16 累加,只需复制部分逻辑。
综合结果对比
| 指标 | LA (Late Acc.) | EA (Early Acc.) | FADD32 (参考) |
|---|---|---|---|
| 面积 (sq.μm) | 1133 | 674 | 404 |
| 寄存器数 | 345 | 434 | N/A |
| 增量面积 | 572 (SoP 逻辑) | 674 (整体) | - |
| 流水级 | 4 cycles | 4 cycles | 2 cycles |
| 工艺 / 频率 | 5nm / 3.6GHz | 5nm / 3.6GHz | 5nm / 3.6GHz |
| FP32 加法器复用 | 可以 | 不可以 | - |
| 适用场景 | 高性能 CPU | 专用加速器 | - |
总结
LA 设计适合已有高性能 FP32 加法器的 CPU 数据通路,只需增加 SoP 前端逻辑,增量面积小。EA 设计面积更紧凑,适合专用 AI 加速器中作为独立 DOT4 单元部署。两者都支持 E4M3/E5M2 双格式、7-bit 缩放因子、FP32 累加,可扩展到 2-way 和 n-way 点积。
Lutz et al., "Fused FP8 4-Way Dot Product With Scaling and FP32 Accumulation," IEEE 31st Symposium on Computer Arithmetic (ARITH), 2024. DOI: 10.1109/ARITH61463.2024.00016
微架构发展与比较
Nvidia GPGPU 微架构演进
| uArch | Year | Core | SM(X/M) | GPC | TPC | INT32+FP32 | INT32/FP32 | INT32 | FP32 | FP64 | Warp. | Disp. | LD/ST | SFU | Tens.Core |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Fermi | 2010 | GF100 | 16 | 4 | - | 32 | - | - | - | - | 2 | 2 | 16 | 4 | - |
| Kepler | 2012 | GK210 | 15 | - | - | 192 | - | - | - | 64 | 4 | 8 | 32 | 32 | - |
| Maxwell | 2014 | GM204 | 16 | 4 | - | 128 | - | - | - | - | 4 | 8 | 32 | 32 | - |
| Pascal | 2016 | GP100 | 60 | 6 | 5 | 64 | - | - | - | 32 | 2 | 4 | 16 | 16 | - |
| Volta | 2017 | GV100 | 84 | 6 | 7 | - | - | 64 | 64 | 32 | 4 | 4 | 32 | 16 | 8 (1th) |
| Turing | 2018 | TU102 | 72 | 6 | 6 | - | - | 64 | 64 | 2 | 4 | 4 | 16 | 16 | 8 (2th) |
| Ampere | 2020 | GA100 | 128 | 8 | 8 | - | - | 64 | 64 | 32 | 4 | 4 | 32 | 16 | 4 (3th) |
| Ampere | 2020 | GA102 | 84 | 7 | 6 | - | 64 | - | 64 | 2 | 4 | 4 | 16 | 16 | 4 (3th) |
| Ada | 2022 | AD102 | 144 | 12 | 6 | - | 64 | - | 64 | 2 | 4 | 4 | 16 | 16 | 4 (4th) |
| Hopper | 2022 | GH100 | 144 | 8 | 9 | - | - | 64 | 128 | 64 | 4 | 4 | 32 | 16 | 4 (4th) |
| Blackwell | 2024 | - | - | - | - | - | - | - | - | - | - | - | - | - | 4 (5th) |
| Rubin | 2026 | - | - | - | - | - | - | - | - | - | - | - | - | - | 4 (6th) |
Nvidia 微架构存储层次发展
| uArch | Year | Core | Reg/File | Shared Mem | L1$ | L2$ | SMEM+L1 Config | Cache Strategy | Memory Interface |
|---|---|---|---|---|---|---|---|---|---|
| Tesla | 2006 | G80 | 8KB | 16KB | - | - | - | - | GDDR3 |
| Fermi | 2010 | GF100 | 32KB | 48KB | 16KB | 768KB | Configurable | Write-Back | GDDR5 |
| Kepler | 2012 | GK110 | 64KB | 64KB | 64KB | 1.5MB | Configurable | Write-Back | GDDR5 |
| Maxwell | 2014 | GM204 | 64KB | 96KB | 32KB | 2MB | Fixed Split | Write-Through | GDDR5 |
| Pascal | 2016 | GP102 | 64KB | 64/96KB | 32KB | 2MB | Fixed Split | Write-Through | GDDR5X |
| Volta | 2017 | GV100 | 64KB | 96KB | 128KB | 6MB | Fixed Split | Write-Through | HBM2 |
| Turing | 2018 | TU102 | 64KB | 64KB | 4KB | 5.5MB | Fixed Split | Write-Through | GDDR6 |
| Ampere | 2020 | GA102 | 64KB | 164KB | - | 40MB | 128KB Shared | - | GDDR6X/HBM2e |
| Ada | 2022 | AD102 | 64KB | 99KB | - | 50MB | 128KB Shared | - | GDDR6X |
| Hopper | 2022 | GH100 | 64KB | 256KB | - | 50MB | 256KB Shared | - | HBM3 |
| Blackwell | 2024 | GB200 | 64KB | 228KB | - | 140MB | 228KB Shared | - | HBM3e |
| Rubin | 2026 | TBD | TBD | TBD | - | TBD | TBD | - | HBM4 |
注: Shared Memory / L1 Cache 大小在不同架构中有不同的配置策略。存储层次结构说明:
- Register File (寄存器文件): 每个 SM 内部的高速存储,供线程使用
- Shared Memory (共享内存): 每个 SM 内部,供该 SM 内所有线程块共享
- L1$ (L1缓存): 每个 SM 级别的缓存
- L2$ (L2缓存): 芯片全局缓存,所有 SM 共享
- Memory Interface (内存接口): 连接到外部 GDDR/HBM 内存
Fermi
Fermi
2010 首个完整 GPU 计算架构- Fermi 是 NVIDIA 第一个面向通用计算设计的完整架构。每个 SM 包含 32 个 CUDA Core,分布在 2 条 lane 上(每条 16 个)。
- Fermi 架构把 Tesla 架构的 TPC 改名为 Graphics Processor Clusters(GPC),毕竟 Texture 现在显得不再那么重要。
- Fermi 的 CUDA core 实现了浮点乘加融合(FMA),每个 CUDA Core 内部是 1 个单精度浮点单元 (FPU) + 1 个整数单元 (ALU),可以直接执行 FMA 操作。每个 cycle 可跑 16 个双精度 FMA。Tesla 的浮点并没有完全按照 IEEE754 标准实现,例如不支持 subnormal 浮点,而 Fermi 实现了完整的支持,并且实现了 IEEE754 标准的 rounding mode。
- Fermi 架构把 Load/Store(LD/ST)单元独立出来,地址空间也从 32 位扩大到了 64 位。寄存器堆保存了 32768 个 32 位寄存器。
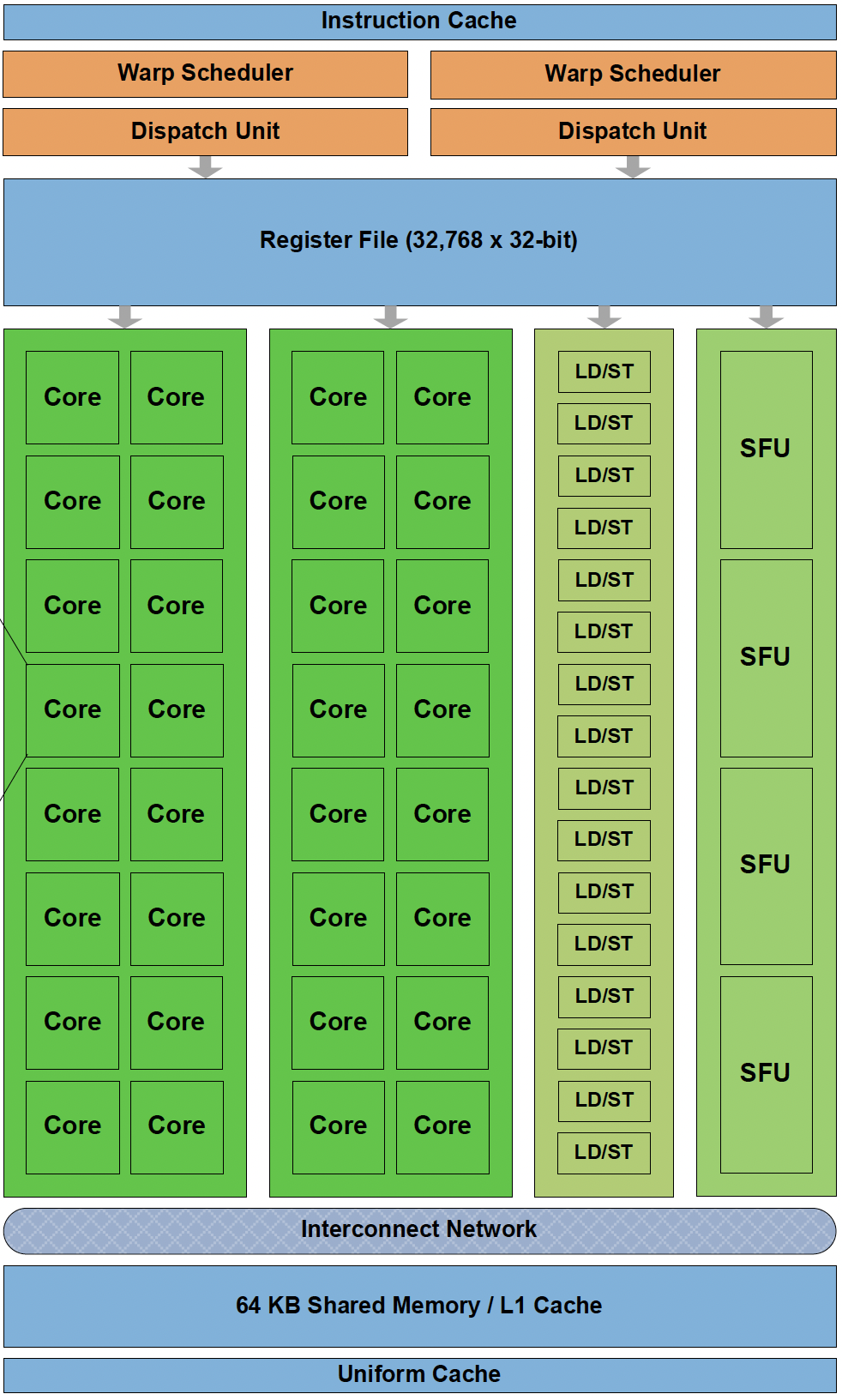
Fermi 规模+存储层次
- Fermi 架构引入了 L1 和 L2 数据缓存。
- Fermi 架构的 Shared Memory 和 L1 数据缓存大小是可配置的,二者共享 64 KB 的空间,可以选择 48KB Shared Memory 加 16KB 的 L1 数据缓存,也可以选择 16KB Shared Memory 和 48KB 的 L1 数据缓存。
- Fermi 架构的 L2 缓存采用的是 写回(write-back) 策略。
Fermi References
Kepler
Kepler
2012 SMX FP64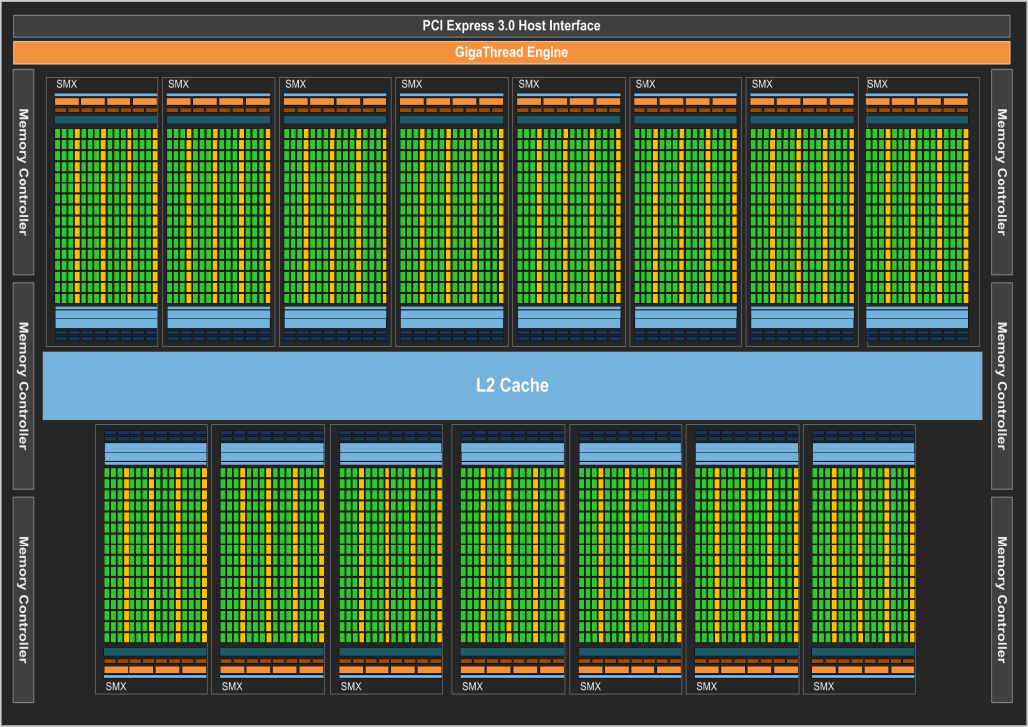
- Kepler 去掉了 TPC/GPC 这一个层级,而是把 SM 做的很大,称为 SMX。相比 Fermi 大幅堆料:CUDA Core 从 32 暴增到 192(4 × 3 × 16,每条 lane 仍是 16 个)。
- Kepler 引入 独立的 64 个双精度运算单元,不需要通过单精度单元去做双精度运算。这使得 Kepler 的双精度性能远超前后几代。4 个 Warp Scheduler 搭配 8 个 Dispatch Unit(1:2 比例)。
- Kepler 相比 Fermi 架构的主要改进:
- Dynamic Parallelism 和 Grid Management Unit:不仅 CPU 可以提交任务到 GPU 执行,GPU 自己也可以提交任务到自己上去执行
- Hyper-Q:允许多个 CPU 核心同时向 GPU 提交任务,把硬件任务队列从 1 增加到了 32 个。每个 CUDA stream 会对应到一个硬件任务队列,因此增加硬件任务队列,可以减少 false dependency。
- GPUDirect:支持 RDMA
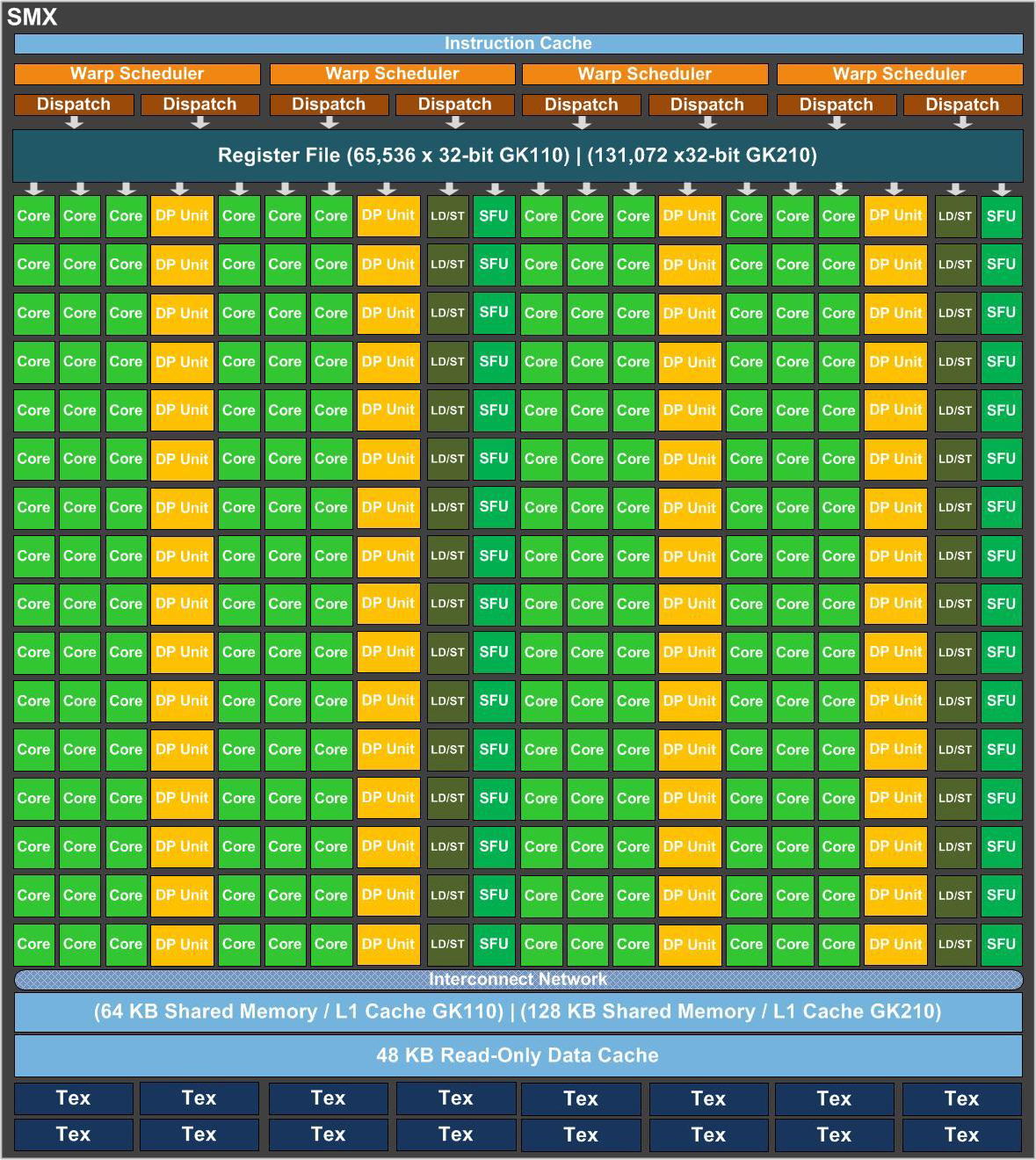
Kepler 规模+存储层次 (GK210)
- Kepler 引入了一个额外的 48KB 只读 Data Cache,用于保存只读的数据,可以提供相比 Shared/L1 cache 更高的性能。
- 根据 Dissecting the NVIDIA Volta GPU Architecture via Microbenchmarking,Kepler 架构每个周期每个 SM 可以读取 256 字节的数据,也就是说,每个 LD/ST unit 每周期可以读取 4 字节的数据。
Kepler References
Maxwell
Maxwell
2014 SMM 能效比优先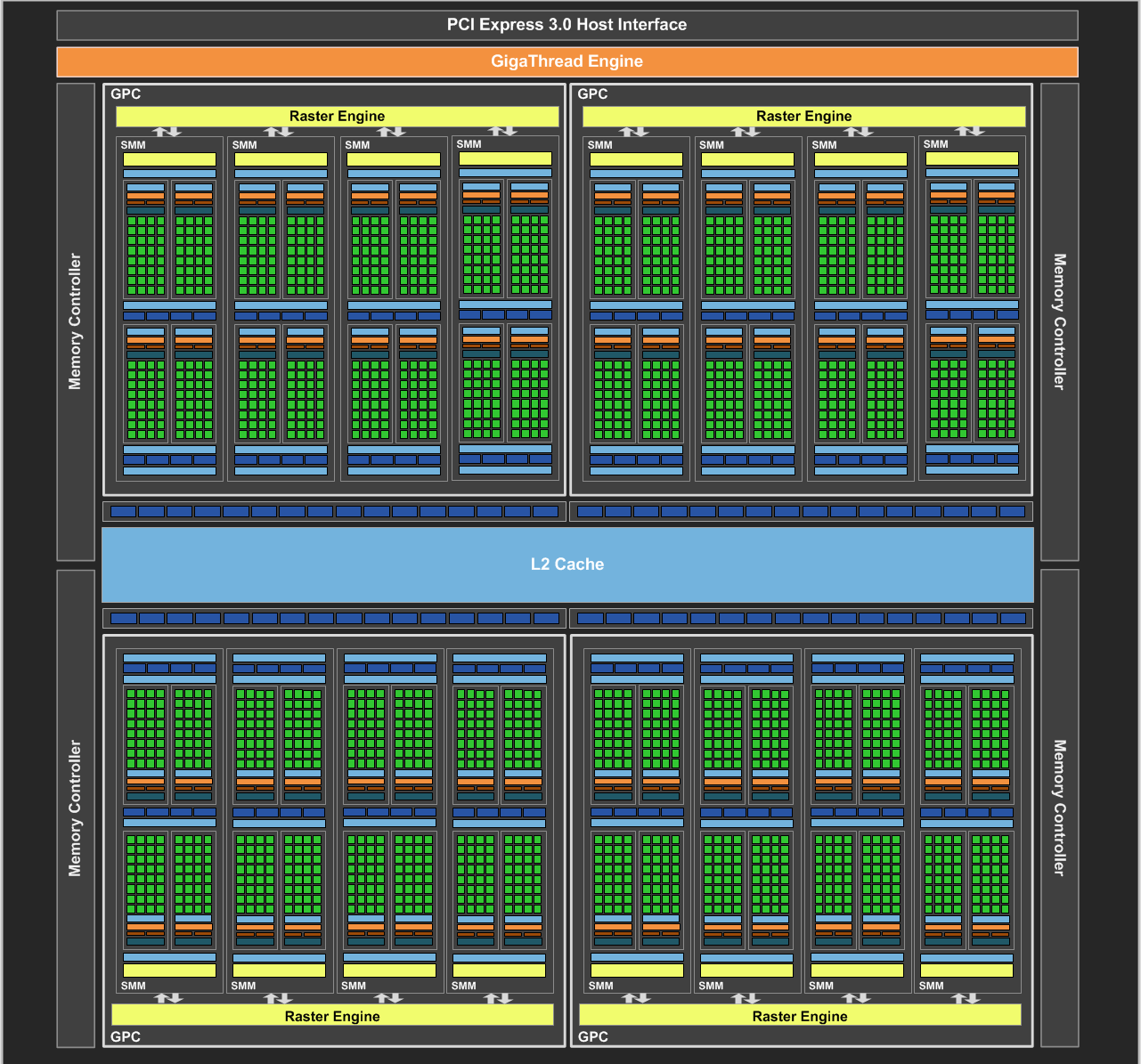
- 虽然 Kepler 把 GPC 层次去掉了,但是 Maxwell 架构又把 GPC 加回来了。
- SM 更名为 SMM。开始做减法:移除独立双精度计算单元,CUDA Core 从 192 精简到 128(4 × 32)。
- Maxwell 把计算单元也划分成了四份,每一份叫做一个 Processing Block(PB),每个 Block 有独立的 Warp Scheduler、Instruction Buffer 和 Register File。
- 工艺提升带来的收益:每个 CUDA Core 性能比 Kepler 提升 1.4x,整体能效比提升 2x。
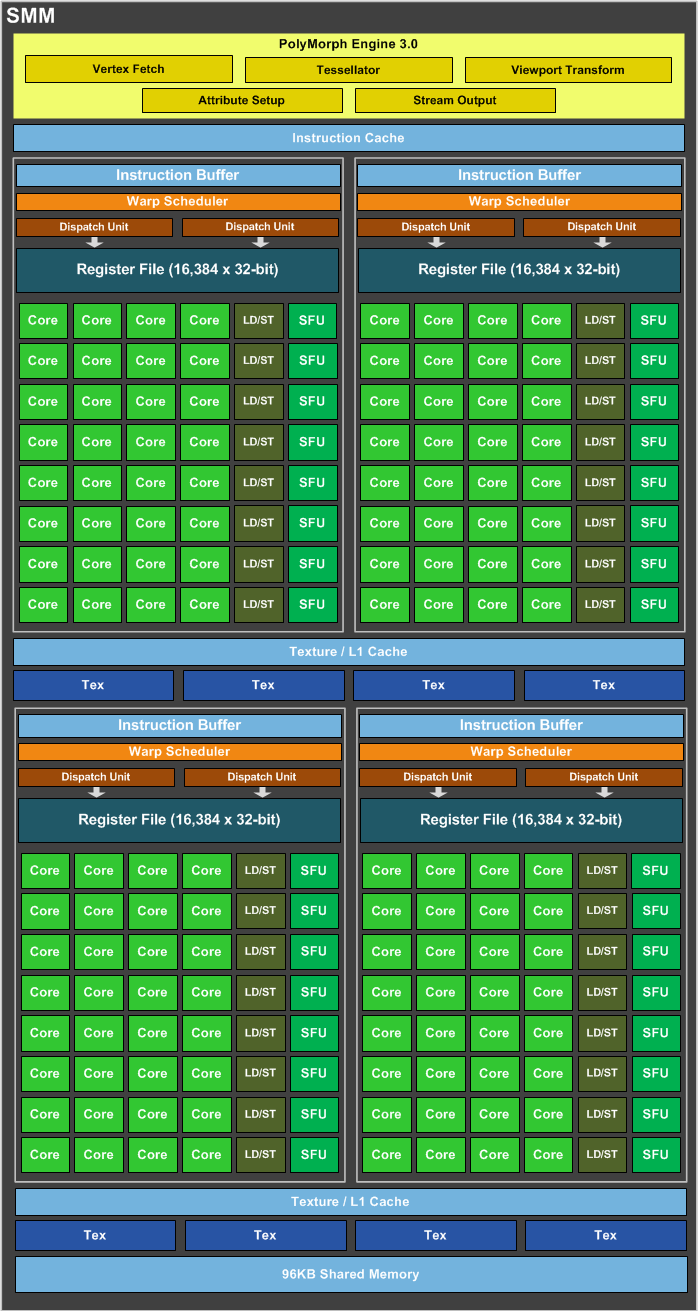
Maxwell 规模+存储层次 (gm204,最大规模芯片 gm200 无官方文档)
- Maxwell 架构的 L1 缓存和 Shared Memory 不再共享,Shared Memory 独占 96KB,然后 L1 缓存和 Texture 缓存共享空间。
- 根据 Dissecting the NVIDIA Volta GPU Architecture via Microbenchmarking,Maxwell 架构每个周期每个 SM 可以读取 256 字节的数据,也就是说,每个 LD/ST unit 每周期可以读取 4 字节的数据。
Maxwell References
Pascal
Pascal
2016 FP16 NVLink
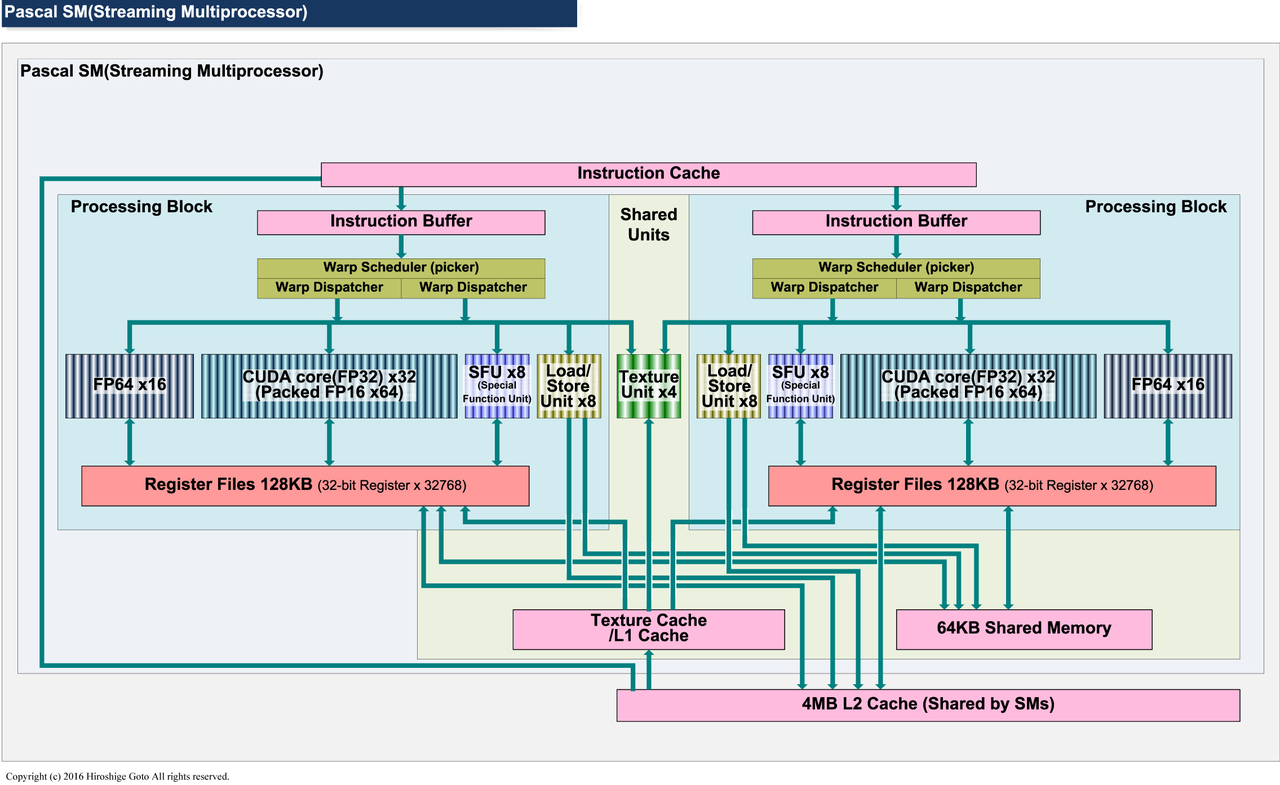
- Pascal 架构每个 SM 只有 2 个 PB。
- NVLink:首次引入 GPU 间高速互联 NVLink 1.0,双向带宽 160 GB/s
- SM 内部进一步精简:2 × 32 = 64 CUDA Core,Warp Scheduler 也缩减为 2 个。
- 双精度回归:32 个独立 FP64 单元(2 × 16)
- FP16 支持:CUDA Core 首次支持半精度计算,为后续 AI 加速铺路
- 支持 Compute Preemption,使得 kernel 可以在指令级别做抢占,而不是 thread block 级别,这样就可以让调试器等交互式的任务不会阻碍其他计算任务的进行;在 Kepler 架构中,只有等一个 thread block 的所有 thread 完成,硬件才可以做上下文切换,但是如果中间遇到了调试器的断点,这时候 thread block 并没有完成,那么此时只有调试器可以使用 GPU,其他任务就无法在 GPGPU 上执行

Pascal 规模+存储层次 (GP100)
- 支持 Unified Memory,使得 CPU 和 GPU 可以共享虚拟地址空间,让数据自动进行迁移。
- 8 个 512 位的内存控制器,每个内存控制器附带 512 KB L2 缓存,总共有 4096 KB 的 L2 缓存。
- 每两个内存控制器为一组,连接到 4 个 1024 位的 HBM2 内存。
- Pascal 架构每个 SM 有 64 KB 的 Shared memory,并且 SM 的数量比 Maxwell 的两倍还要多,因此实际上是在变相地增加 Shared memory 的数量、容量以及带宽。
- 根据 Dissecting the NVIDIA Volta GPU Architecture via Microbenchmarking,Pascal 架构每个周期每个 SM 可以读取 128 字节的数据,也就是说,每个 LD/ST unit 每周期可以读取 8 字节的数据。
Pascal SM 微架构图
Pascal References
Volta
Volta
2017 V100 Tensor Core 诞生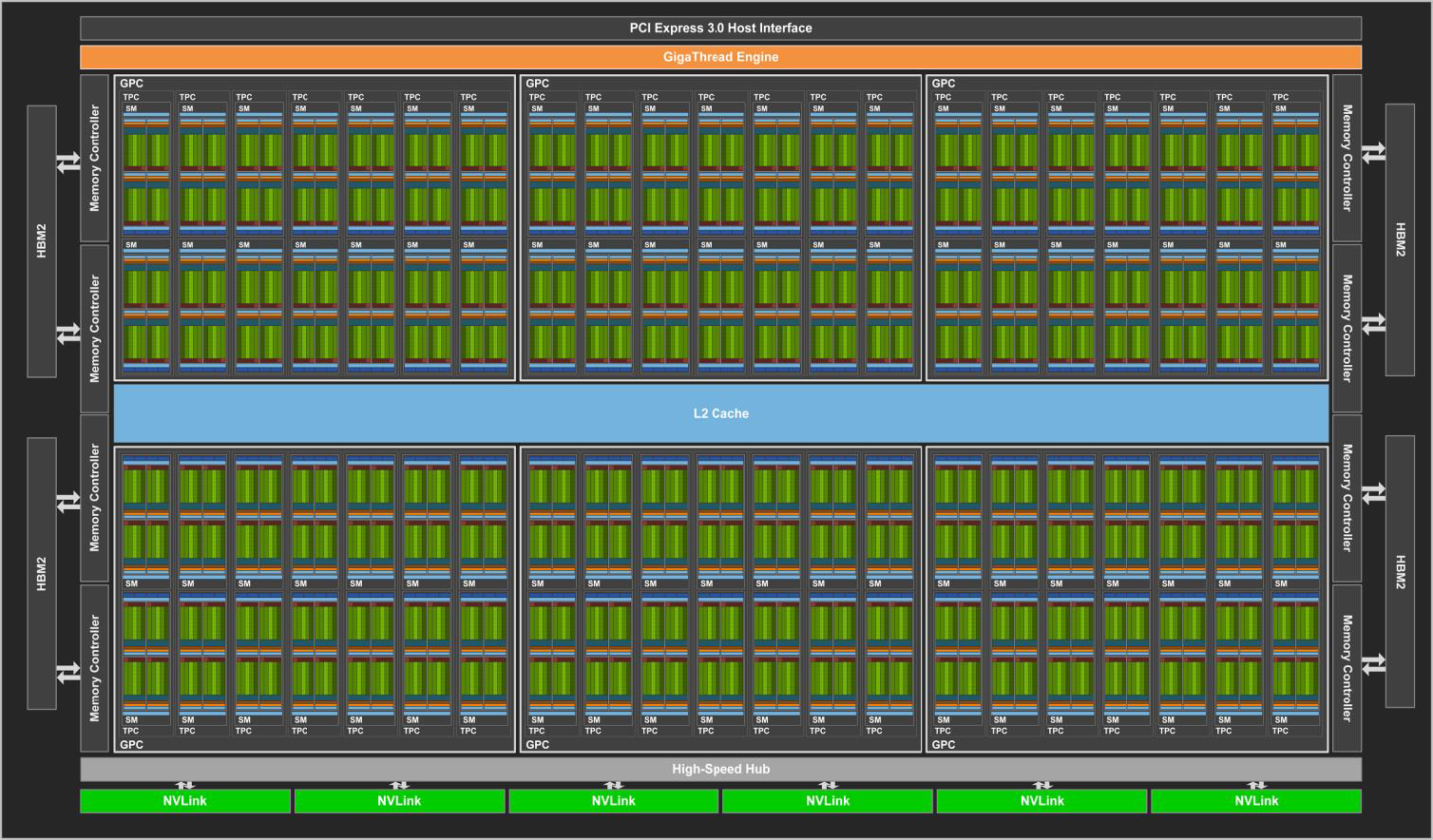
- 里程碑架构。
- Tensor Core 1.0:每个 SM 8 个(4 × 2),每个 TC 每周期执行 4×4×4 GEMM(FP16 输入,FP32 累加),等效 64 个 FP32 ALU。
- NVLink 2.0
- CUDA Core 拆分:不再是统一的 FPU+ALU,而是独立的 FP32 Core 和 INT32 Core。优势:两者可以同时执行,混合运算吞吐翻倍。
- 独立线程调度:每个线程拥有独立 PC 和调用栈
- Warp Scheduler 变为 1:1 对应 Dispatch Unit(之前是 1:2),并增加 L0 ICache。
- 每个 SM 拆分成 4 个 PB 回归。
- Volta 的 Warp Scheduler 又回到了单发射,一条涉及 32 条线程的指令被发射,那么它需要两个周期来完成,第二个周期的时候,Warp Scheduler 也会同时发射其他指令,从而实现指令级并行。
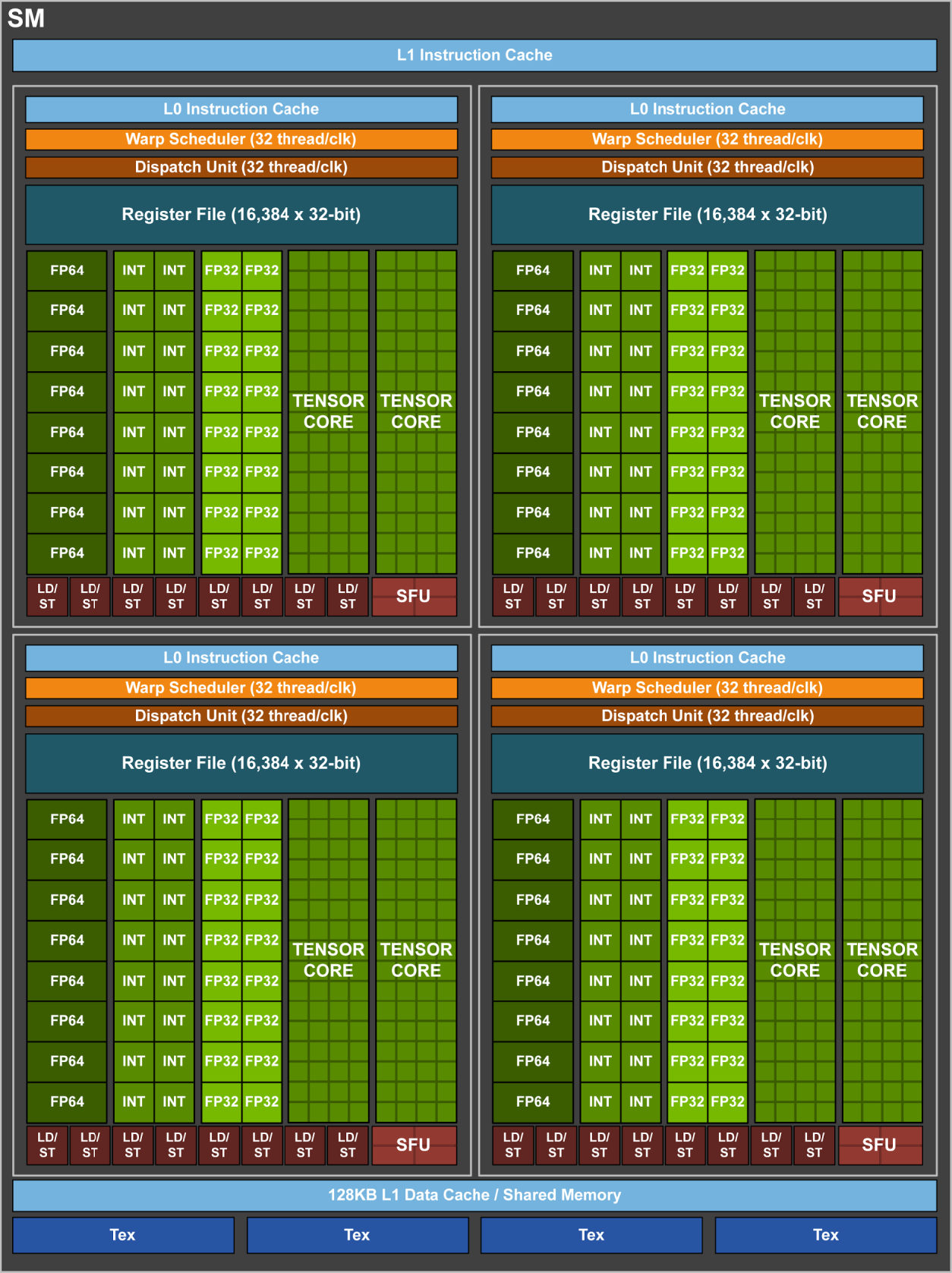
Volta 规模+存储层次 (GV100)
- 在 Volta 架构中,L1 Data Cache 和 Shared memory 再次共享。
- 引入了 L0 Instruction Cache,每个 Processing Block 内部都有一个。
- 8 个 512 位的内存控制器。
- 根据 Dissecting the NVIDIA Volta GPU Architecture via Microbenchmarking,Volta 架构每个周期每个 SM 可以读取 256 字节的数据,也就是说,每个 LD/ST unit 每周期可以读取8 字节的数据。
- 根据 gpu-benches 实测,每个 SM 每周期只能读取不到 128 字节(14 TB/s,80 个 SM,时钟频率 1530 MHz,每个 SM 每周期读取 114 字节)的数据(V100不是完整GV100核心,拥有 80 个 SM)。
- 6144 KB 的 L2 缓存
- 分为 64 个 L2 slice,每个 slice 是 96 KB 的大小。
- 每个 slice 每周期可以读取 32 B 的数据,因此整个 L2 缓存的读带宽是 2048 字节每周期。
- L2 缓存工作在和 SM 同一个频率下,按 1530 MHz 频率来算,L2 缓存带宽是 3.133 TB/s,V100 的内存带宽是 0.9 TB/s,每个 SM 每个周期可以分到的 L2 带宽是 25.6 字节。
Volta SIMT 改进:独立线程调度
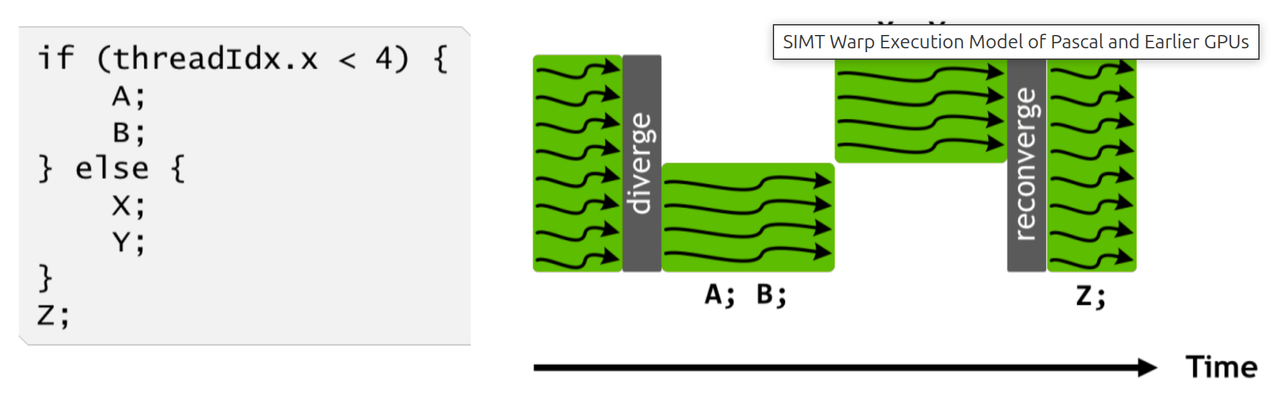
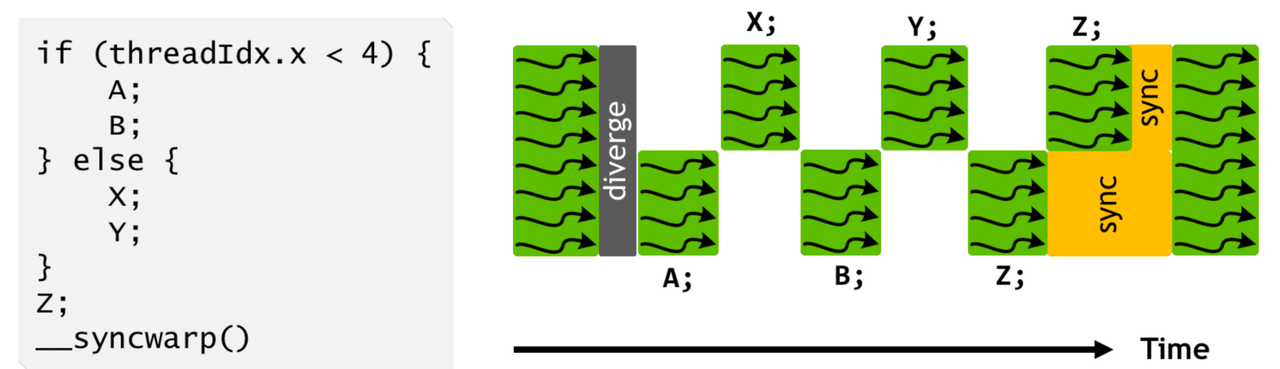
Pascal 及之前,一个 Warp 遇到分支时两侧只能串行执行。Volta 将 PC 和调用栈设计为每个线程独立,分支内的指令可以在更细的粒度上混合调度,并支持 __syncwarp() 显式同步。
Volta References
Turing
Turing
2018 RTX 20 系列 RT Core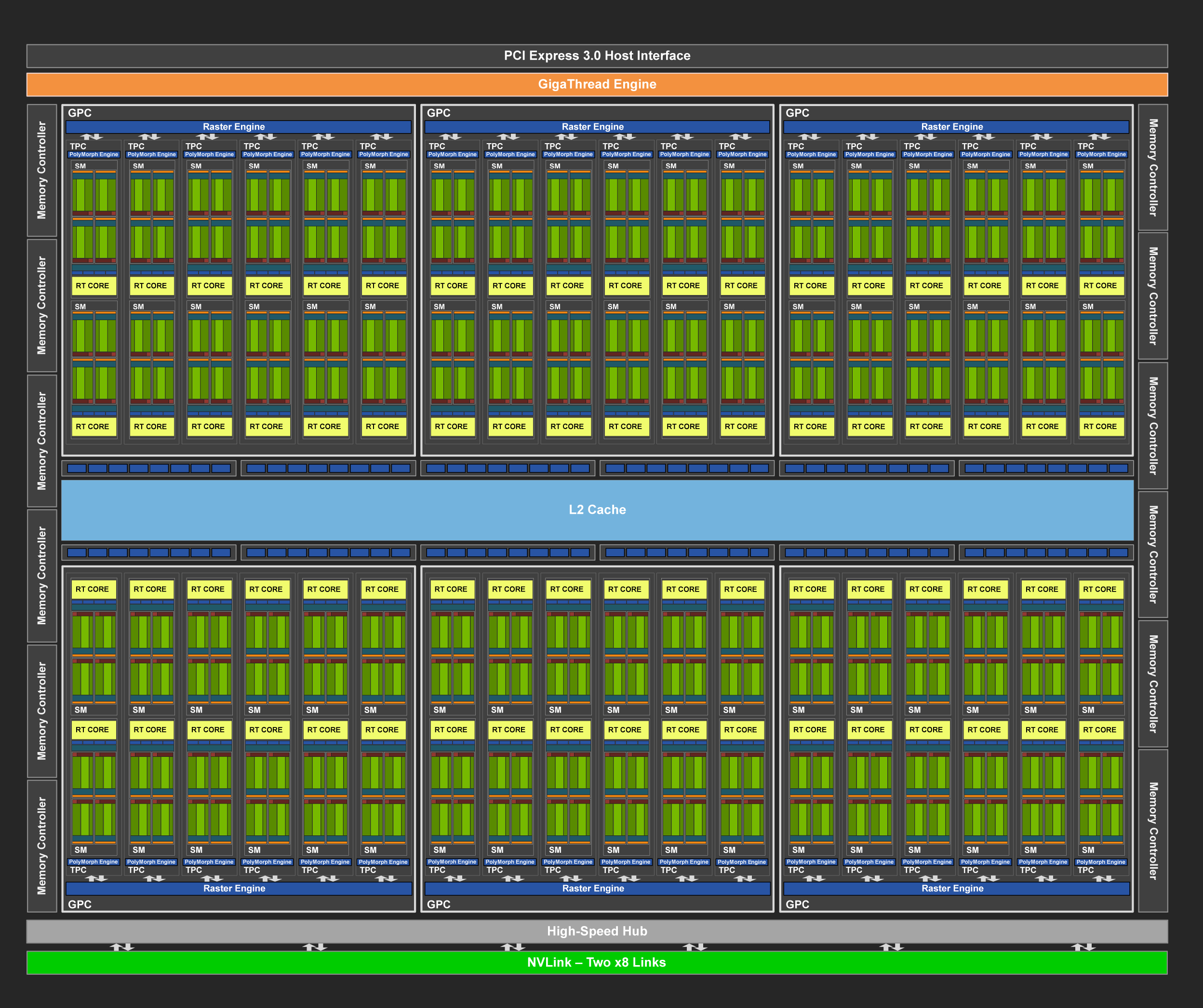
- Tensor Core 2.0:在 Volta 基础上新增 INT8 和 INT4 支持,开始覆盖推理量化场景。
- 引入 RT Core(光线追踪加速单元)。
- SM 内计算单元与 Volta 类似,每个 SM 含 4 个 Processing Block。
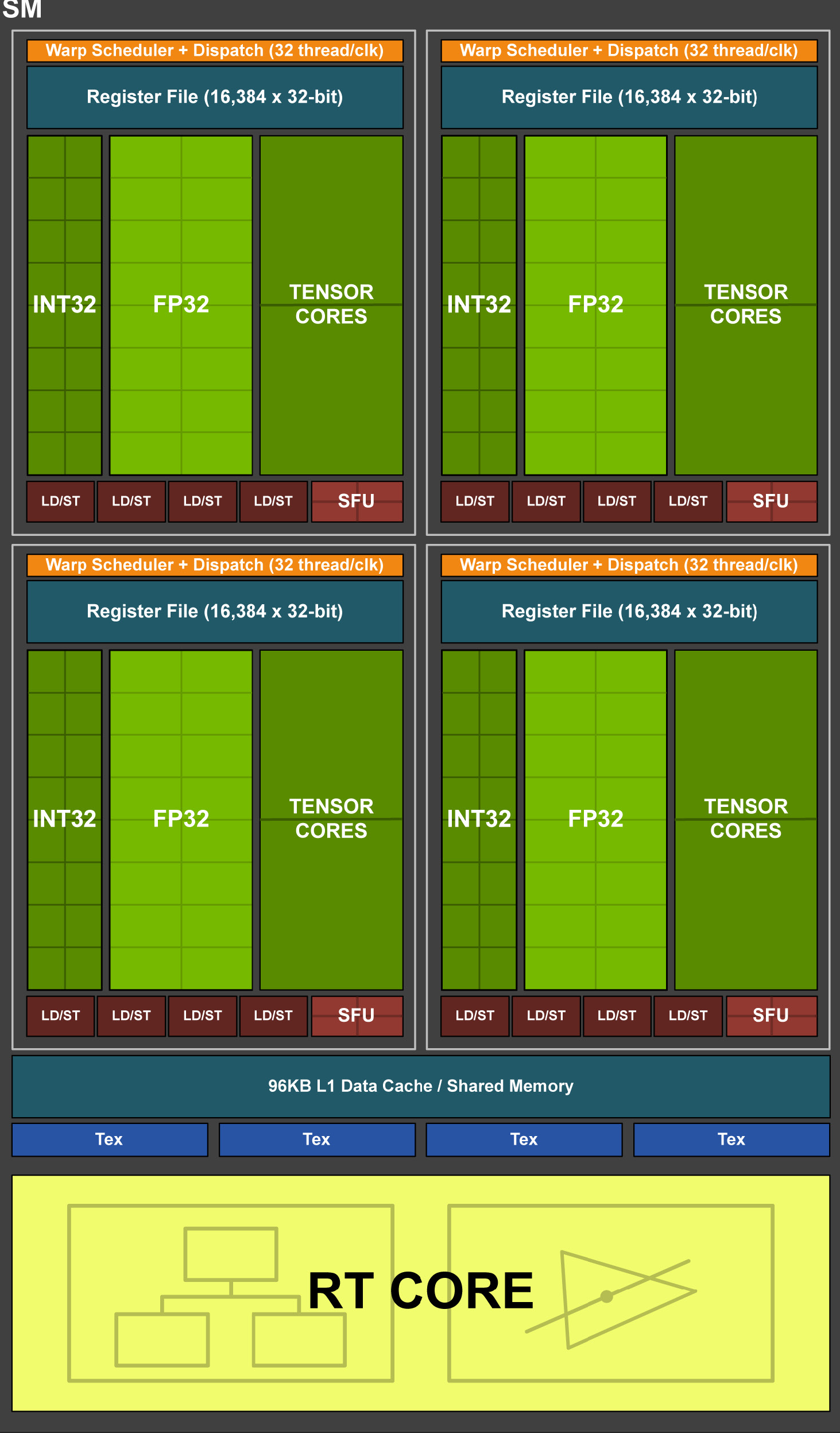
Turing 规模+存储层次 (TU102)
- 12 个 32-bit GDDR6 memory controller
- Turing 架构的每 TPC 的 L1 带宽是 Pascal 架构的两倍。
Turing SM 微架构图
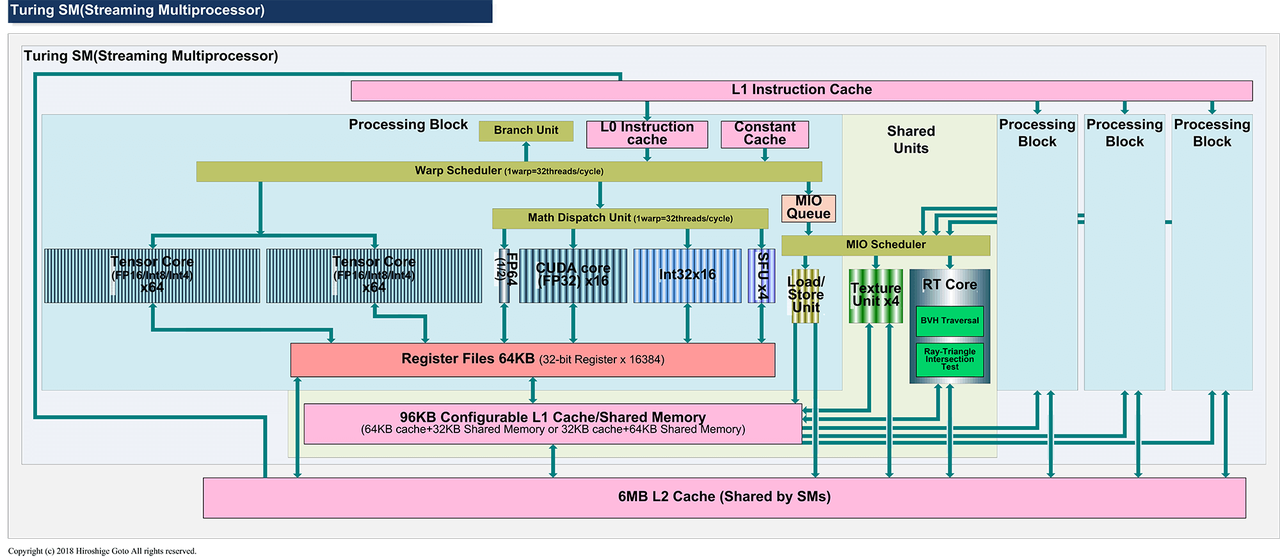
Turing References
Ampere (GA100)
Ampere (GA100)
2020 A100 稀疏 Tensor Core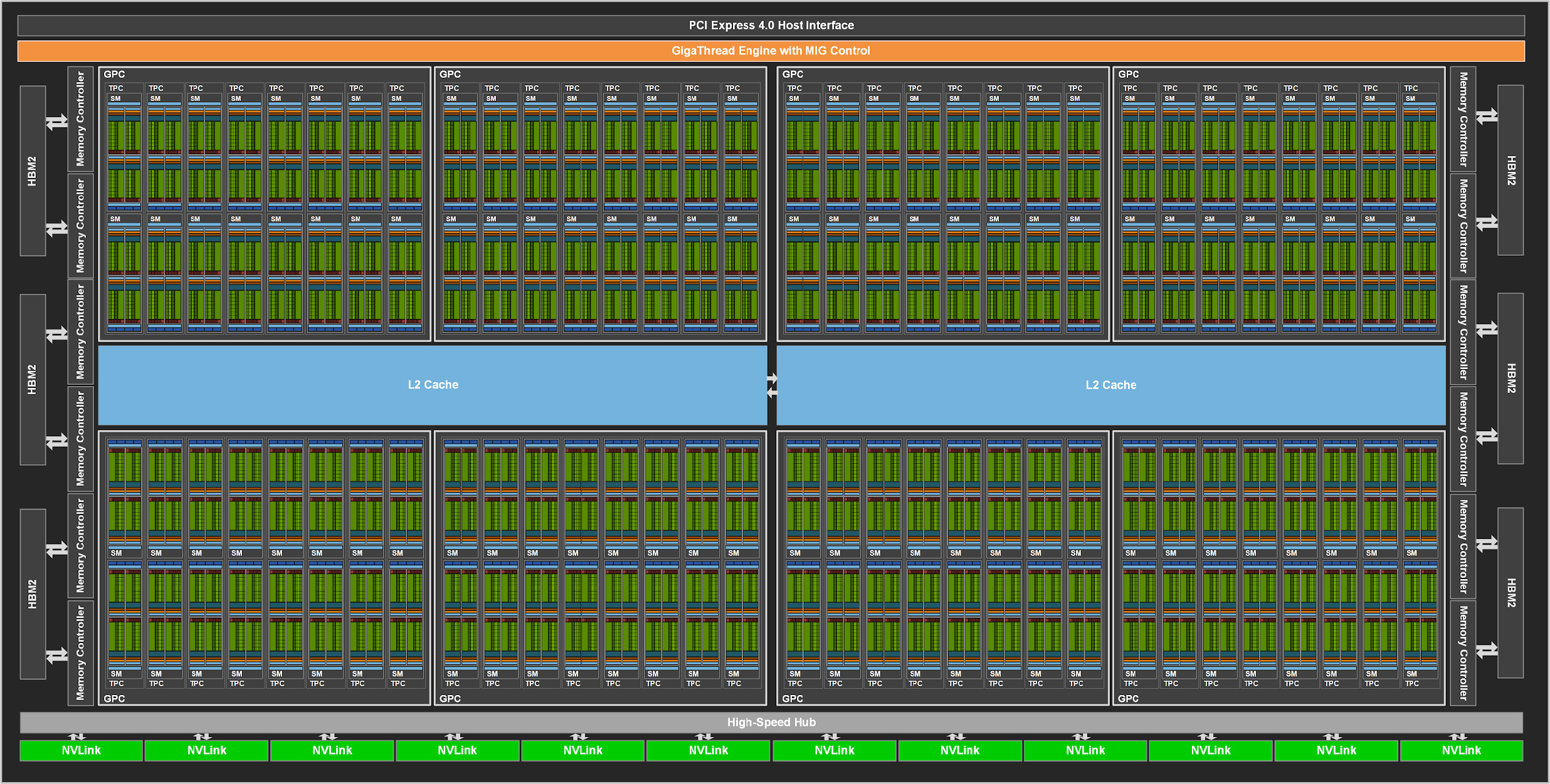
- 4 个 PB。
- Tensor Core 3.0
- 数量从 8 减半到 4,但每个吞吐量翻 4 倍,总吞吐翻倍。
- 数据类型大幅扩展:FP16、BF16、TF32、FP64、INT8、INT4、Binary。
- 支持结构性稀疏矩阵。
- NVLink 3.0
- Multi-Instance GPU(多实例 GPU,MIG 1.0)
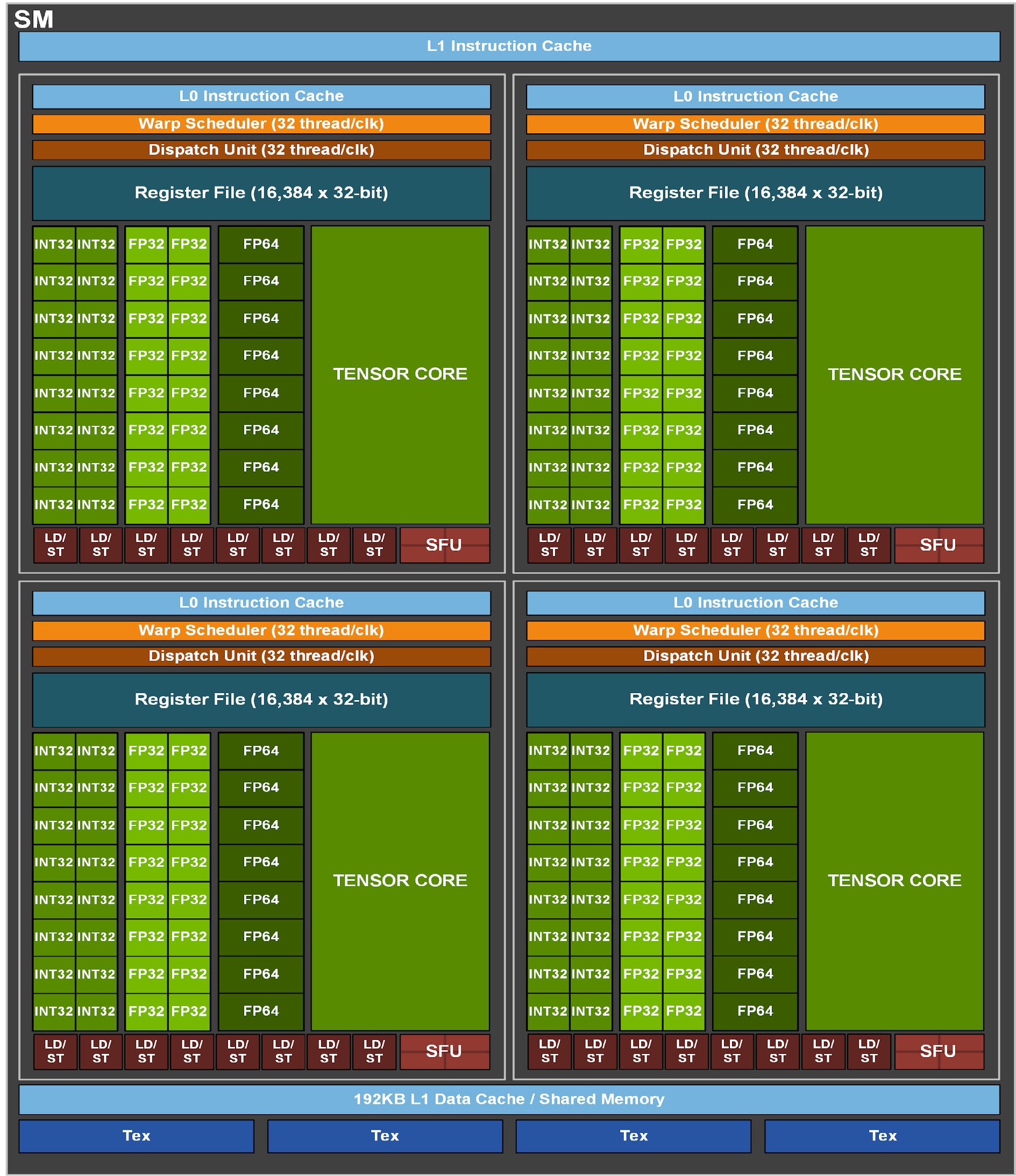
Ampere (GA100) 规模+存储层次
- 6 个 HBM2 stack,对应 12 个 512-bit memory controller。
- 每个 SM 的 L1 Data Cache/Shared Memory 总量增加到了 192 KB。
- A100 GPU 有 40 MB 的 L2 缓存,分为两个 partition。
- 每个 partition 有 40 个 L2 slice,每个 slice 是 512 KB 的大小。
- 每 8 个 L2 slice 对应一个 memory controller
- 每个 slice 每周期可以读取 64B 的数据,因此整个 L2 缓存的读带宽是 5120 字节每周期
- L2 缓存工作在和 SM 同一个频率下,按 1410 MHz 频率来算,L2 缓存带宽是 7.219 TB/s,A100 的内存带宽是 1.555 TB/s,
- 每个 SM 每个周期可以分到的 L2 带宽是 47.4 字节
- 根据 gpu-benches 实测,每个 SM 每周期只能读取不到 128 字节(19 TB/s,108 个 SM,时钟频率 1410 MHz,每个 SM 每周期读取 125 字节)的数据。
- A100 GPU 有 108 个 SM(不是完整的GA100),一共 432 个 Tensor Core,每个 Tensor Core 每周期可以进行 256 个 FP16 FMA 计算,SM 频率 1410 MHz,因此 A100 的 FP16 Tensor Core 峰值性能是 432 * 256 FLOPS * 2 * 1410 MHz = 312 TFLOPS。
Ampere (GA100) A100 vs V100 性能提升

Ampere (GA100) References
Ampere (GA102)
Ampere (GA102)
2020 RTX 30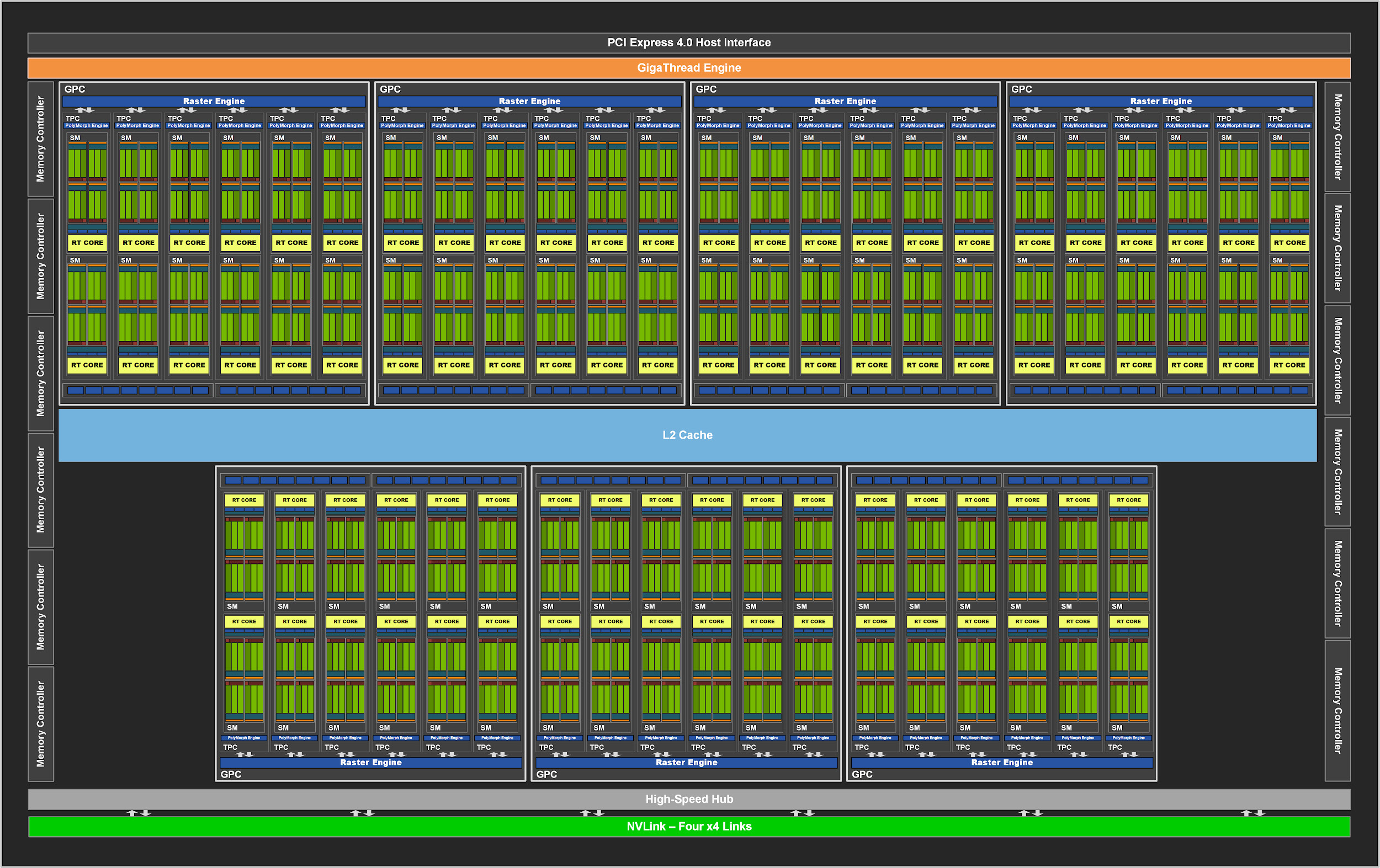
- 4 个 PB。
- 出现了 FP32/INT32 混合的 core,使得 FP32 峰值性能翻倍,但是这个峰值也更难达到,因为达到峰值意味着不用到 FP32/INT32 core 的 INT32 部分。

Ampere (GA102) 规模+存储层次
- 12 个 32-bit memory controller,一共 384 位。
- 12 组 512KB 的 L2 缓存,每组对应一个内存控制器,L2 一共是 6144 KB。
- GA102 的 shared memory 带宽是每个 SM 每个时钟 128 字节,而 Turing 架构的这个值是 64。
- GeForce RTX 3080 (GA102) 的每 SM L1 带宽是 219 GB/s(一个 SM 有 16 个 LD/ST unit,每个 LD/ST unit 每个周期读取 8B 的数据,所以带宽是 219 GB/s)。
- GeForce RTX 2080 Super (TU104) 的每 SM L1 带宽是 116 GB/s(每个 SM 有 16 个 LD/ST unit,每个 LD/ST unit 每个周期读取 4B 的数据,带宽是 116 GB/s)。
Ampere (GA102) SM 微架构图
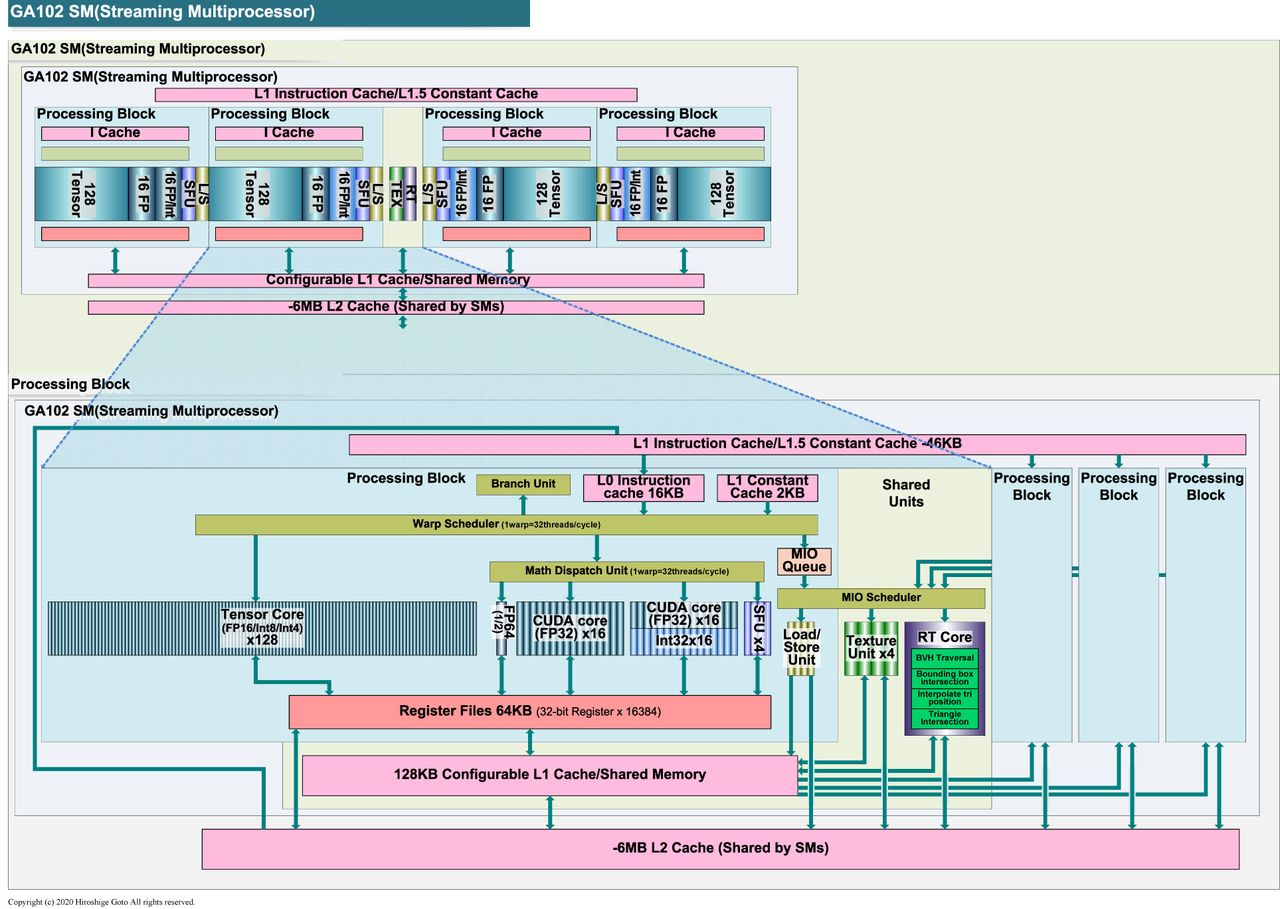
Ampere (GA102) References
Ada Lovelace
Ada Lovelace
2022 RTX 40 系列 FP8 / DLSS 3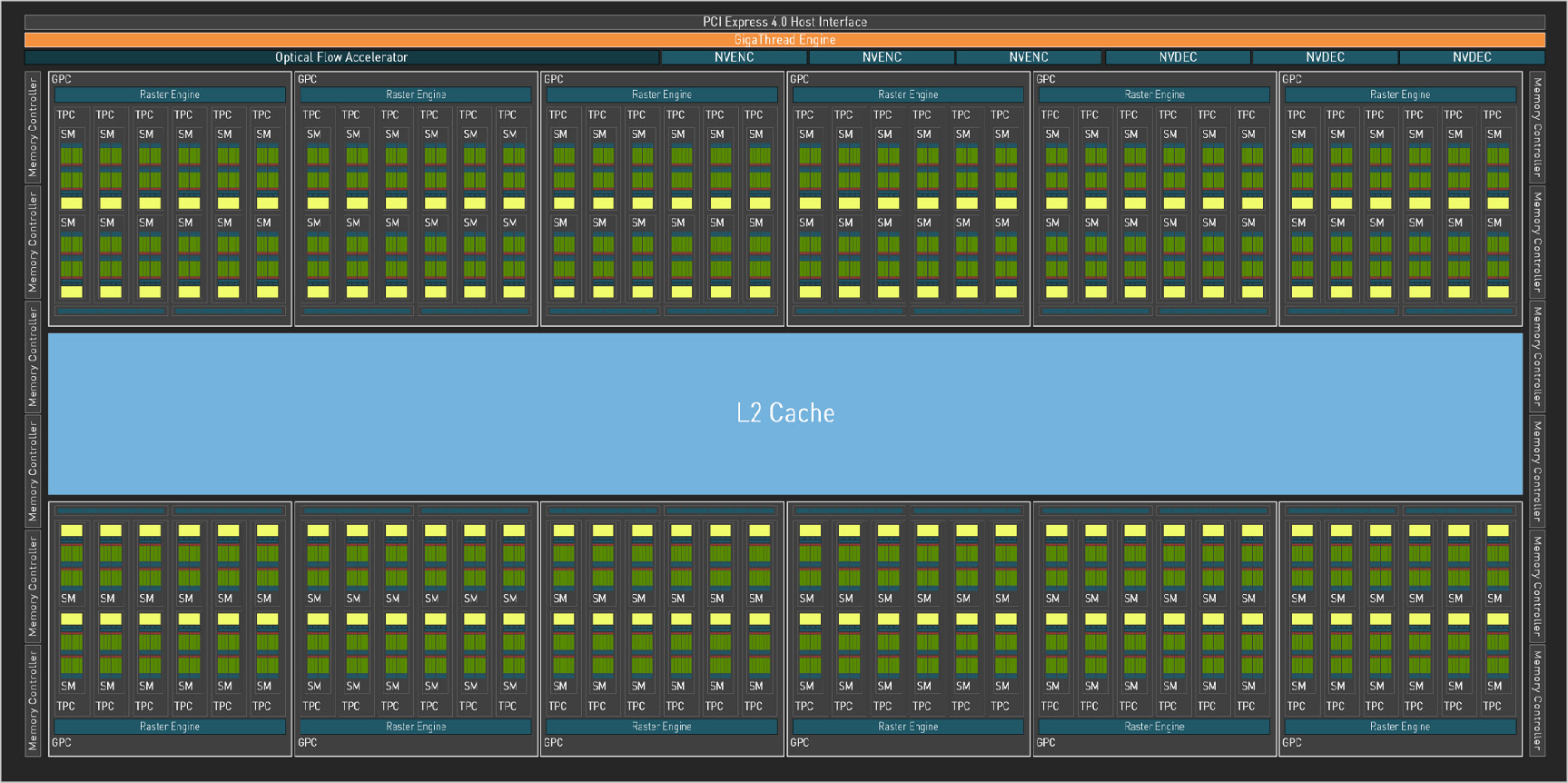
消费级旗舰。延续 Ampere 的双数据通路(64 专用 FP32 + 64 Flex FP32/INT32),合计 128 FP32 Core。TSMC 4N 工艺。
- Tensor Core 4.0:新增 FP8(E4M3 / E5M2)支持,搭载 Hopper 的 Transformer Engine 技术。吞吐量相比 Ampere 再翻倍。
- 第 3 代 RT Core:新增 Opacity Micro-Map(OMM)和 Displaced Micro-Mesh Engine,光追性能 2x。
- 支持 DLSS 3(帧生成)、Shader Execution Reordering(SER,光追调度优化)。
- AD102:144 SM。
- RTX 4090:128 SM。
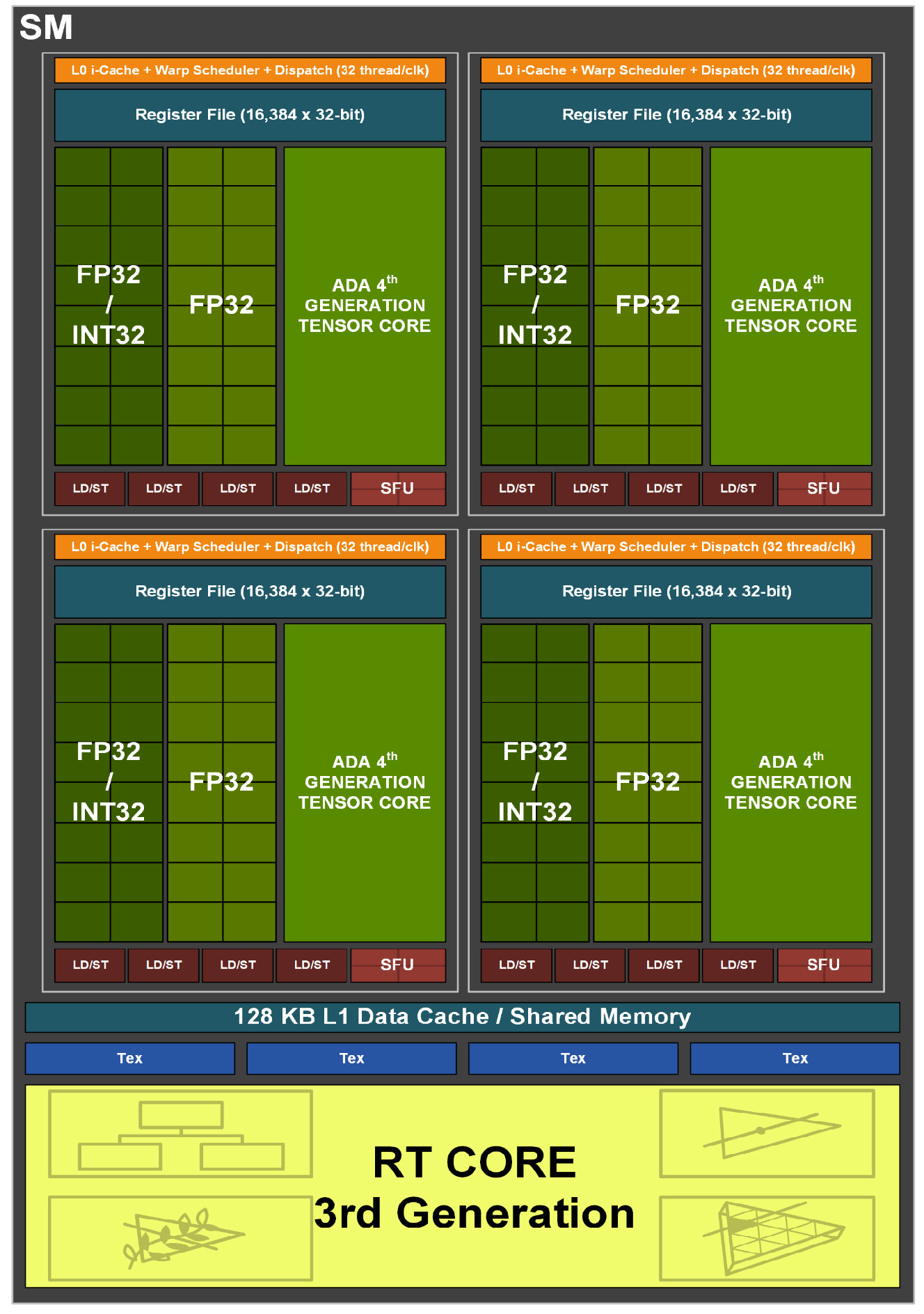
Ada Lovelace 规模+存储层次 (AD102)
- 12 个 32-bit memory controller,一共 384 位。
- L2 缓存大幅扩容:,AD102 达 96MB(Ampere GA102 仅 6MB,16x 增长),显著减少显存访问。
Ada Lovelace References
Hopper
Hopper
2022 H100 / H200 Transformer Engine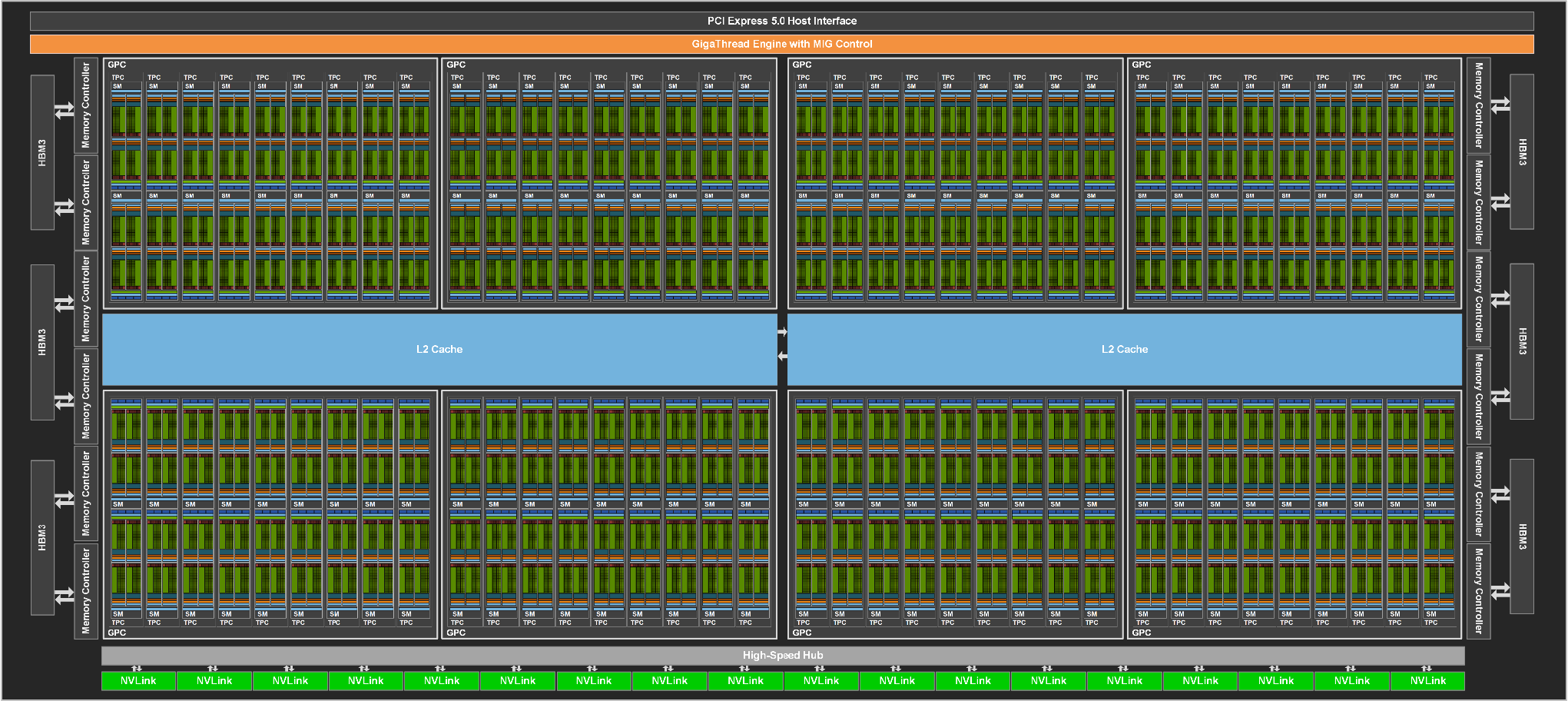
大模型时代的数据中心旗舰。
- 8 个 GPC,66 个 TPC,每个 TPC 有两个 SM;一共 132 个 SM。(H100 SXM5 参数)
- Tensor Core 4.0:
- 原生 FP8 支持(E4M3 / E5M2)。
- 引入
wgmma(Warp Group MMA)指令,128 线程协作完成矩阵运算。 - FP16 吞吐 729 TFLOPS。
- FP8 达 1,448 TFLOPS(H800)。
- Transformer Engine:硬件动态精度选择,每层自动在 FP8 和 FP16 之间切换,训练精度不损失。
- Thread Block Cluster:跨 SM 的线程块协作原语。
- Distributed Shared Memory (DSMEM):SM 间可直接访问彼此的 Shared Memory,延迟 180 cycles,带宽 3.27 TB/s。
- Tensor Memory Accelerator (TMA):异步 1D-5D 张量搬运,解放计算线程。
- DPX 指令集:动态规划算法加速(Smith-Waterman 等),最高 13x 提速。
- H100 SXM5:132 SM,16,896 FP32 Core,528 TC,80GB HBM3(3 TB/s),50MB L2,800 亿晶体管,TSMC N4。
- NVLink 4.0
- MIG 2.0
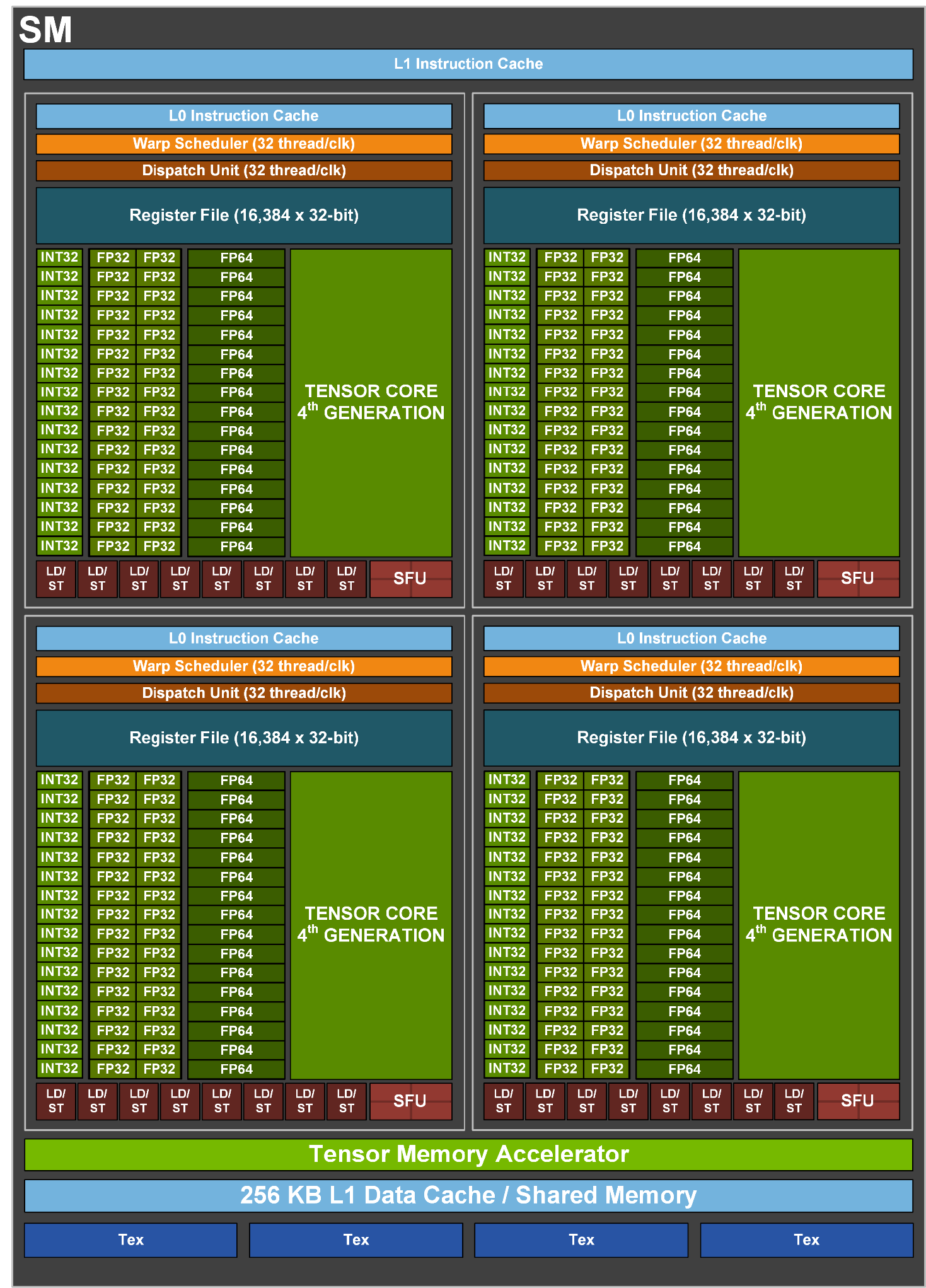
Hopper 规模+存储层次 (GH100)
- Shared Memory + L1 扩大至 256KB。
- HBM3 DRAM,5 个 stack,10 个 512-bit memory controller,总共 80 GB 容量。(H100 SXM5 参数)
- 完整版的 GH100 芯片有 60MB 的 L2 缓存,H100 有 50MB 的 L2 缓存。
- 根据 gpu-benches 实测,每个 SM 每周期只能读取略多于 128 字节(25 TB/s,114 个 SM,时钟频率 1620 MHz,每个 SM 每周期读取 135 字节)的数据。
Hopper CUDA Kernel
CUDA Kernel 之前是三个层次:Grid、Thread Block 和 Thread,分别对应整个 GPU、SM 和 CUDA Core,而这一代引入了 Thread Block Cluster 的层次,变成了四个层次:Grid、Thread Block Cluster、Thread Block 和 Thread。其中 Thread Block 对应 GPC,每个 GPC 有多个 TPC,每个 TPC 有多个 SM。
Hopper References
Blackwell
Blackwell
2024 B100 / B200 FP4 / TMEM双芯片封装,2080 亿晶体管。INT32 和 FP32 执行路径统一,INT32 Core 数量与 FP32 持平。
- Tensor Core 5.0:
- 全新 FP4(e2m1)和 FP6(e3m2 / e2m3)支持。
- FP4 吞吐 7,702 TFLOPS。
- FP8 吞吐 3,851 TFLOPS(B200)。
- 引入
tcgen05.mma单线程 tensor 指令,替代 warp 级 MMA,延迟从 32 cycles 降至 11 cycles。 - Tensor Memory (TMEM):全新的 256KB 专用 Tensor Core 存储,512 列 × 128 lane 的 2D 阵列。读带宽 16 TB/s,写带宽 8 TB/s(每 SM)。缓存未命中延迟降低 58%。
- 硬件解压引擎:原生支持 LZ4、Snappy、Zstd、GZIP 解压。
- B200:148 SM,192GB HBM3e。GB202:192 SM,24,576 FP32 Core,TSMC N4P。
- LLM 性能:Mistral-7B FP8 推理 78,400 tok/s(1.59x vs H200),FP4 达 112,800 tok/s。

Rubin
Rubin
2026 (预计) R100 HBM4- 下一代数据中心平台,预计 2026 下半年。
- Tensor Core 6.0:支持 FP4/FP6/FP8/FP16/BF16/TF32/FP32/FP64。
- 第 3 代 Transformer Engine:硬件自适应压缩 + 跨层动态精度选择 + 双级微块缩放(NVFP4)。
- HBM4 显存:288GB,8 个堆叠,带宽 22 TB/s(Blackwell 的 2.8 倍)。
- NVLink 6.0:每 GPU 双向 3.6 TB/s(NVLink 5.0 的 2 倍)。
- FP4 算力:50 PFLOPS(Blackwell 20 PFLOPS 的 2.5 倍)。
- Vera Rubin NVL72 系统:72 GPU 聚合 FP4 推理 3,600 PFLOPS,NVLink 聚合带宽 260 TB/s。
(待补充)
Tensor Core 架构演进
Tensor Core 是 NVIDIA 从 Volta 架构开始引入的矩阵运算加速单元,专门用于 GEMM(通用矩阵乘法)。每一代都在数据类型支持、吞吐量和稀疏性上做了显著增强。
目录
工作原理
D = A × B + C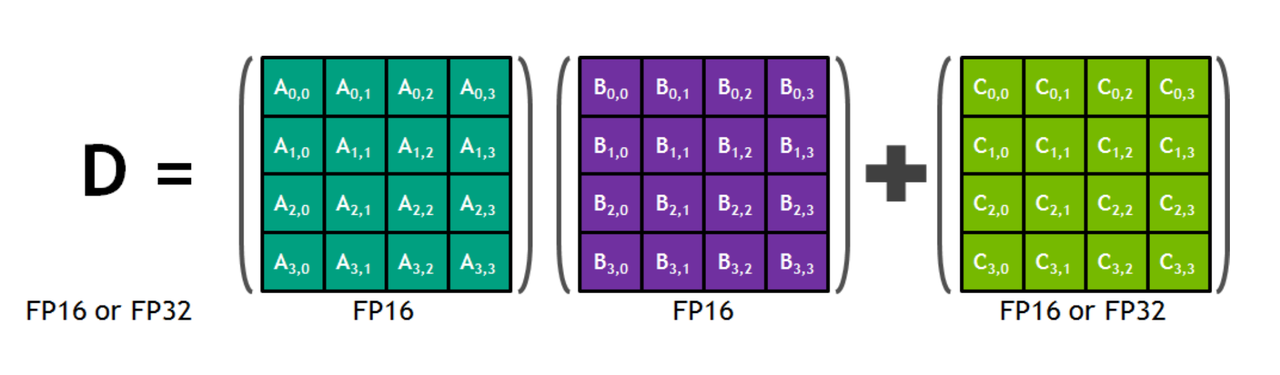
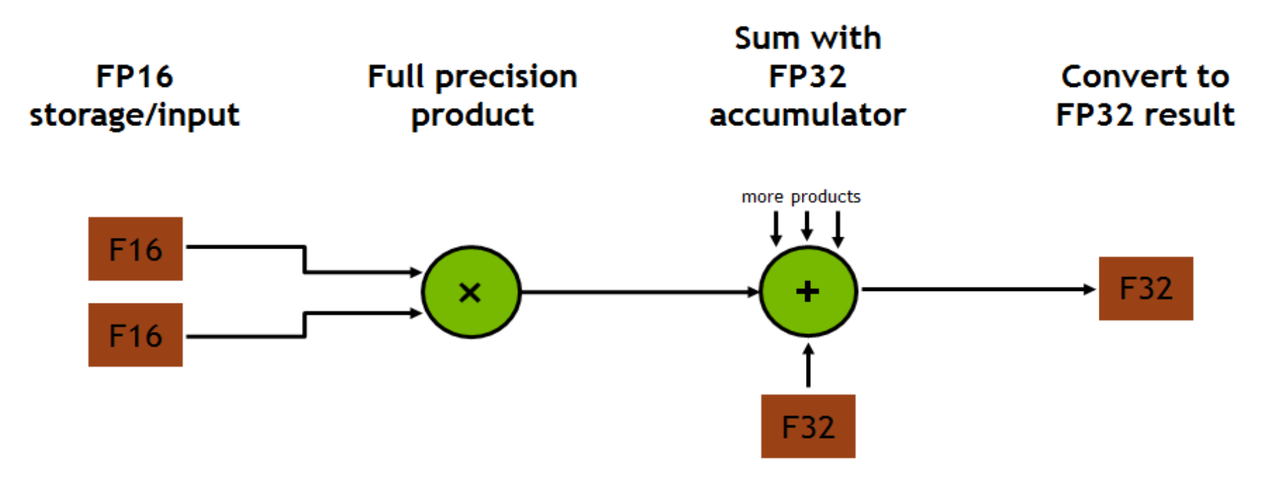
Tensor Core 从寄存器中读取两个 FP16 矩阵 A 和 B,执行全精度乘法,结果累加到 FP16 或 FP32 的累加器 C 中,产生输出 D。每个 Tensor Core 每周期完成一个 4×4×4 GEMM,等效于 64 个 FP32 FMA 操作的算力,能效比极高。
第 1 代 - Volta
2017 V100首代 Tensor Core,每个 SM 中 4 个 Sub-Core 各含 2 个 TC。每个 TC 每周期执行一个 4×4×4 的矩阵乘累加,等效 64 个 FP32 ALU 的算力。仅支持 FP16 输入,输出可选 FP16 或 FP32。
V100 全卡 80 个 SM × 8 TC = 640 个 Tensor Core,FP16 算力 125 TFLOPS。
第 2 代 - Turing
2018 T4 / RTX 20在 Volta 基础上新增 INT8 和 INT4 支持,开始覆盖推理量化场景。使用 INT8 时吞吐量翻倍(2x FP16),INT4 时翻四倍(4x FP16)。
T4 推理卡就是基于 Turing 架构,INT8 推理性能优秀,被广泛用于线上推理服务。
第 3 代 - Ampere
2020 A100 TF32 / BF16 / 稀疏数量从 8 减半到 4,但每个 TC 内部吞吐量翻 4 倍,总吞吐提升 2x。数据类型大幅扩展:
- TF32:自动启用,FP32 代码无需修改即可加速(精度略低)
- BF16:保持 FP32 动态范围,训练更稳定
- FP64:首次支持双精度 Tensor Core,HPC 场景受益
- Binary:极致压缩的二值运算
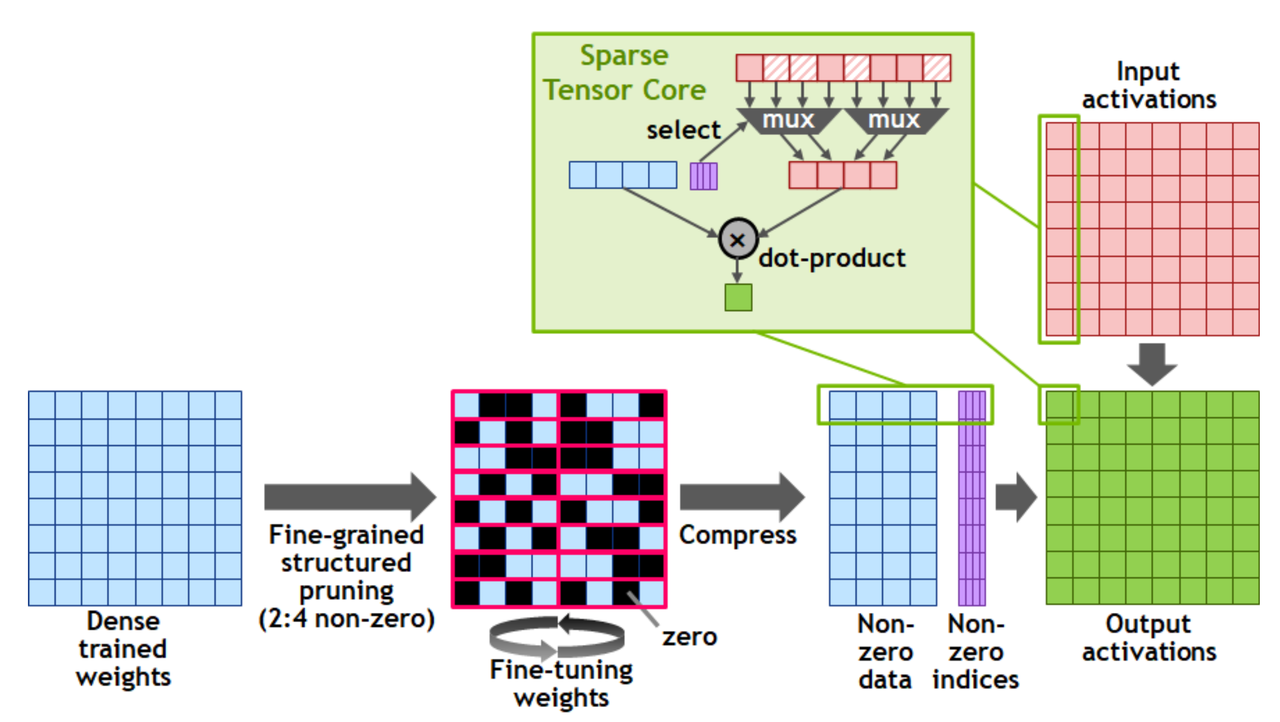
结构化稀疏 (2:4)
Ampere 首创 硬件级加速Ampere 的 Tensor Core 引入了硬件级结构化稀疏加速。与传统 CSR/BSR 等稀疏格式完全不同,采用 2:4 稀疏模式:每 4 个权重中剪掉 2 个。
压缩后的数据包含两部分:
- Non-zero data:压缩后的权重数据(原来的一半大小)
- Non-zero indices:记录非零元素位置的索引矩阵
硬件内部通过 MUX(多路选择器)根据 indices 从 activation 中选取对应元素,与压缩后的权重做点积。实现近 2x 推理加速,且无需修改模型代码。
第 4 代 - Ada / Hopper
2022 FP8 原生 Transformer EngineAda(消费级)和 Hopper(数据中心)共享第 4 代 Tensor Core 设计,核心新增:
- FP8 原生支持:E4M3(激活/权重)和 E5M2(梯度),吞吐量相比 FP16 翻倍
- Transformer Engine(Hopper):硬件动态精度选择,每层自动在 FP8 和 FP16 之间切换,训练精度无损
- wgmma 指令(Hopper):Warp Group MMA,128 线程协作完成矩阵运算,大幅提高寄存器利用率
H800 实测吞吐:FP8 1,448 TFLOPS,FP16 729 TFLOPS,TF32 364 TFLOPS,FP8 稀疏 2,945 TFLOPS。
第 5 代 - Blackwell
2024 FP4 / FP6 TMEMBlackwell 的 Tensor Core 是一次底层架构重构:
- FP4 / FP6:全新超低精度格式。FP4 (e2m1) 吞吐 7,702 TFLOPS,FP6 (e3m2/e2m3) 5,134 TFLOPS(B200)
- tcgen05.mma:单线程 Tensor 指令,替代 Hopper 的 warp 级 wgmma。延迟从 32 cycles 降至 11 cycles(m64n64k16),降幅 2.9-11.6x
- Tensor Memory (TMEM):256KB 专用存储,512 列 × 128 lane 的 2D 阵列。读 16 TB/s,写 8 TB/s(每 SM)。Tensor Core 直接从 TMEM 读写,不再争抢寄存器和 Shared Memory
B200 实测:FP8 3,851 TFLOPS(1.27x H200),FP16 1,929 TFLOPS,FP32 481 TFLOPS。
第 6 代 - Rubin
2026 预计 50 PFLOPS FP4第 3 代 Transformer Engine:硬件自适应压缩 + 跨层动态精度选择 + 双级微块缩放(NVFP4)。
FP4 算力 50 PFLOPS(Blackwell 20 PFLOPS 的 2.5x)。Vera Rubin NVL72 系统聚合 3,600 PFLOPS FP4 推理。